

{kind=link}
Understanding methods to use the robots.txt file is essential for any web site’s search engine marketing technique. Errors on this file can impression how your web site is crawled and your pages’ search look. Getting it proper, alternatively, can enhance crawling effectivity and mitigate crawling points.
Google just lately reminded web site house owners in regards to the significance of utilizing robots.txt to dam pointless URLs.
These embrace add-to-cart, login, or checkout pages. However the query is – how do you utilize it correctly?
On this article, we’ll information you into each nuance of methods to just do so.
What Is Robots.txt?
The robots.txt is an easy textual content file that sits within the root listing of your web site and tells crawlers what ought to be crawled.
The desk under supplies a fast reference to the important thing robots.txt directives.
| Directive | Description |
| Person-agent | Specifies which crawler the foundations apply to. See consumer agent tokens. Utilizing * targets all crawlers. |
| Disallow | Prevents specified URLs from being crawled. |
| Permit | Permits particular URLs to be crawled, even when a guardian listing is disallowed. |
| Sitemap | Signifies the placement of your XML Sitemap by serving to search engines like google and yahoo to find it. |
That is an instance of robotic.txt from ikea.com with a number of guidelines.
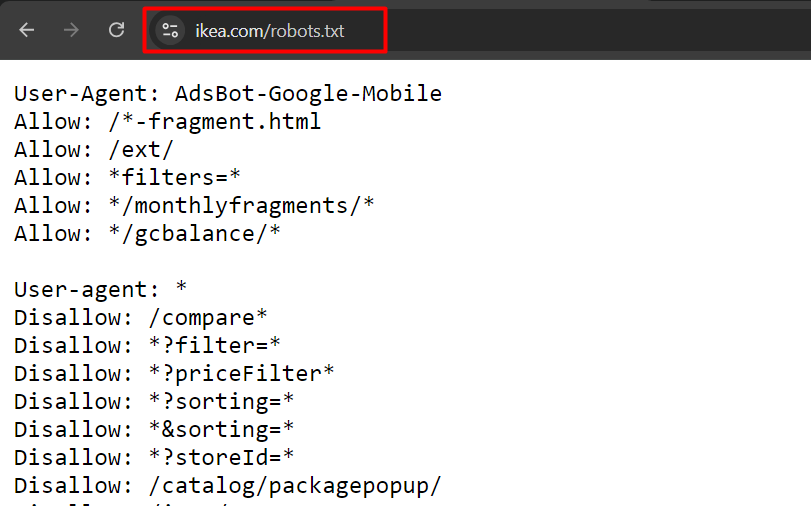 Instance of robots.txt from ikea.com
Instance of robots.txt from ikea.comWord that robots.txt doesn’t help full common expressions and solely has two wildcards:
- Asterisks (*), which matches 0 or extra sequences of characters.
- Greenback signal ($), which matches the top of a URL.
Additionally, observe that its guidelines are case-sensitive, e.g., “filter=” isn’t equal to “Filter=.”
Order Of Priority In Robots.txt
When organising a robots.txt file, it’s vital to know the order by which search engines like google and yahoo determine which guidelines to use in case of conflicting guidelines.
They comply with these two key guidelines:
1. Most Particular Rule
The rule that matches extra characters within the URL shall be utilized. For instance:
Person-agent: *
Disallow: /downloads/
Permit: /downloads/free/On this case, the “Permit: /downloads/free/” rule is extra particular than “Disallow: /downloads/” as a result of it targets a subdirectory.
Google will permit crawling of subfolder “/downloads/free/” however block all the things else underneath “/downloads/.”
2. Least Restrictive Rule
When a number of guidelines are equally particular, for instance:
Person-agent: *
Disallow: /downloads/
Permit: /downloads/Google will select the least restrictive one. This implies Google will permit entry to /downloads/.
Why Is Robots.txt Vital In search engine marketing?
Blocking unimportant pages with robots.txt helps Googlebot focus its crawl price range on useful elements of the web site and on crawling new pages. It additionally helps search engines like google and yahoo save computing energy, contributing to higher sustainability.
Think about you’ve a web-based retailer with a whole lot of 1000’s of pages. There are sections of internet sites like filtered pages that will have an infinite variety of variations.
These pages don’t have distinctive worth, basically include duplicate content material, and will create infinite crawl house, thus losing your server and Googlebot’s assets.
That’s the place robots.txt is available in, stopping search engine bots from crawling these pages.
If you happen to don’t do this, Google might attempt to crawl an infinite variety of URLs with totally different (even non-existent) search parameter values, inflicting spikes and a waste of crawl price range.
When To Use Robots.txt
As a basic rule, you must at all times ask why sure pages exist, and whether or not they have something price for search engines like google and yahoo to crawl and index.
If we come from this precept, actually, we must always at all times block:
- URLs that include question parameters corresponding to:
- Inside search.
- Faceted navigation URLs created by filtering or sorting choices if they don’t seem to be a part of URL construction and search engine marketing technique.
- Motion URLs like add to wishlist or add to cart.
- Non-public elements of the web site, like login pages.
- JavaScript information not related to web site content material or rendering, corresponding to monitoring scripts.
- Blocking scrapers and AI chatbots to forestall them from utilizing your content material for his or her coaching functions.
Let’s dive into how you need to use robots.txt for every case.
1. Block Inside Search Pages
The commonest and completely needed step is to dam inner search URLs from being crawled by Google and different search engines like google and yahoo, as nearly each web site has an inner search performance.
On WordPress web sites, it’s often an “s” parameter, and the URL seems like this:
https://www.instance.com/?s=googleGary Illyes from Google has repeatedly warned to dam “motion” URLs as they will trigger Googlebot to crawl them indefinitely even non-existent URLs with totally different mixtures.
Right here is the rule you need to use in your robots.txt to dam such URLs from being crawled:
Person-agent: *
Disallow: *s=*- The Person-agent: * line specifies that the rule applies to all internet crawlers, together with Googlebot, Bingbot, and so on.
- The Disallow: *s=* line tells all crawlers to not crawl any URLs that include the question parameter “s=.” The wildcard “*” means it might match any sequence of characters earlier than or after “s= .” Nevertheless, it won’t match URLs with uppercase “S” like “/?S=” since it’s case-sensitive.
Right here is an instance of a web site that managed to drastically cut back the crawling of non-existent inner search URLs after blocking them by way of robots.txt.
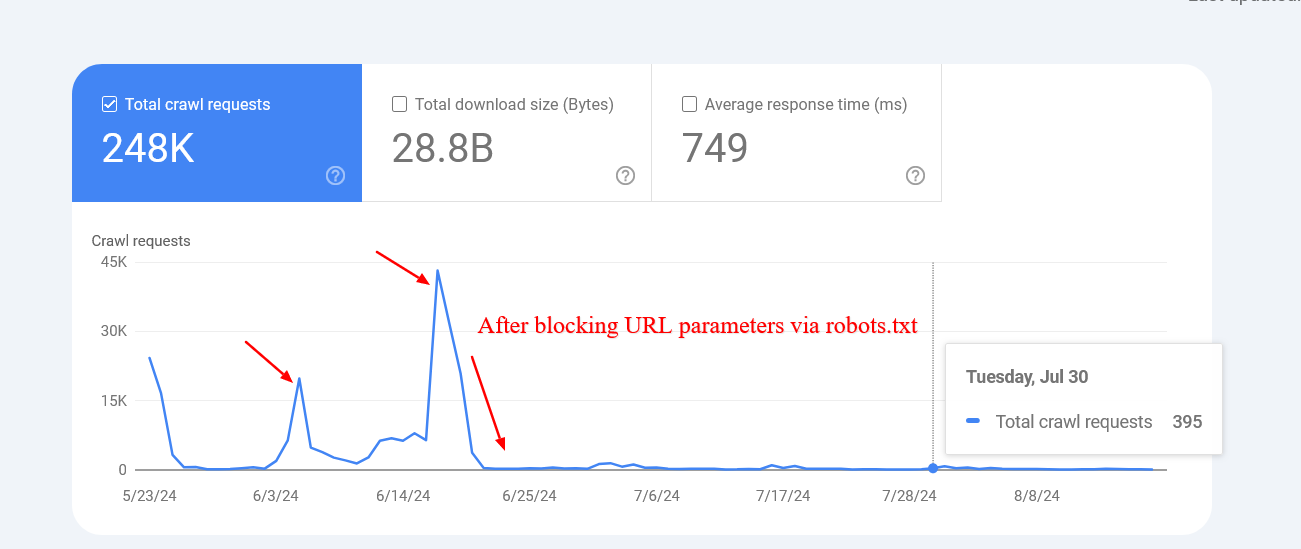 Screenshot from crawl stats report
Screenshot from crawl stats reportWord that Google might index these blocked pages, however you don’t want to fret about them as they are going to be dropped over time.
2. Block Faceted Navigation URLs
Faceted navigation is an integral a part of each ecommerce web site. There may be instances the place faceted navigation is a part of an search engine marketing technique and aimed toward rating for basic product searches.
For instance, Zalando makes use of faceted navigation URLs for colour choices to rank for basic product key phrases like “grey t-shirt.”
Nevertheless, typically, this isn’t the case, and filter parameters are used merely for filtering merchandise, creating dozens of pages with duplicate content material.
Technically, these parameters aren’t totally different from inner search parameters with one distinction as there could also be a number of parameters. You want to be sure you disallow all of them.
For instance, in case you have filters with the next parameters “sortby,” “colour,” and “value,” you might use this algorithm:
Person-agent: *
Disallow: *sortby=*
Disallow: *colour=*
Disallow: *value=*Primarily based in your particular case, there could also be extra parameters, and you might want so as to add all of them.
What About UTM Parameters?
UTM parameters are used for monitoring functions.
As John Mueller said in his Reddit submit, you don’t want to fret about URL parameters that hyperlink to your pages externally.
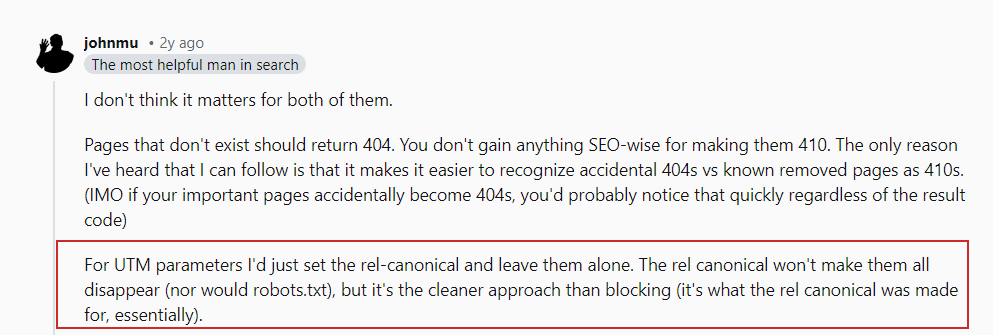 John Mueller on UTM parameters
John Mueller on UTM parametersSimply make certain to dam any random parameters you utilize internally and keep away from linking internally to these pages, e.g., linking out of your article pages to your search web page with a search question web page “https://www.instance.com/?s=google.”
3. Block PDF URLs
Let’s say you’ve a number of PDF paperwork, corresponding to product guides, brochures, or downloadable papers, and also you don’t need them crawled.
Right here is an easy robots.txt rule that can block search engine bots from accessing these paperwork:
Person-agent: *
Disallow: /*.pdf$The “Disallow: /*.pdf$” line tells crawlers to not crawl any URLs that finish with .pdf.
Through the use of /*, the rule matches any path on the web site. Consequently, any URL ending with .pdf shall be blocked from crawling.
If in case you have a WordPress web site and wish to disallow PDFs from the uploads listing the place you add them by way of the CMS, you need to use the next rule:
Person-agent: *
Disallow: /wp-content/uploads/*.pdf$
Permit: /wp-content/uploads/2024/09/allowed-document.pdf$You’ll be able to see that we’ve got conflicting guidelines right here.
In case of conflicting guidelines, the extra particular one takes precedence, which suggests the final line ensures that solely the precise file positioned in folder “wp-content/uploads/2024/09/allowed-document.pdf” is allowed to be crawled.
4. Block A Listing
Let’s say you’ve an API endpoint the place you submit your information from the shape. It’s probably your kind has an motion attribute like motion=”/kind/submissions/.”
The difficulty is that Google will attempt to crawl that URL, /kind/submissions/, which you probably don’t need. You’ll be able to block these URLs from being crawled with this rule:
Person-agent: *
Disallow: /kind/By specifying a listing within the Disallow rule, you’re telling the crawlers to keep away from crawling all pages underneath that listing, and also you don’t want to make use of the (*) wildcard anymore, like “/kind/*.”
Word that it’s essential to at all times specify relative paths and by no means absolute URLs, like “https://www.instance.com/kind/” for Disallow and Permit directives.
Be cautious to keep away from malformed guidelines. For instance, utilizing /kind with out a trailing slash may even match a web page /form-design-examples/, which can be a web page in your weblog that you simply wish to index.
Learn: 8 Widespread Robots.txt Points And How To Repair Them
5. Block Person Account URLs
If in case you have an ecommerce web site, you probably have directories that begin with “/myaccount/,” corresponding to “/myaccount/orders/” or “/myaccount/profile/.”
With the highest web page “/myaccount/” being a sign-in web page that you simply wish to be listed and located by customers in search, you might wish to disallow the subpages from being crawled by Googlebot.
You should utilize the Disallow rule together with the Permit rule to dam all the things underneath the “/myaccount/” listing (besides the /myaccount/ web page).
Person-agent: *
Disallow: /myaccount/
Permit: /myaccount/$
And once more, since Google makes use of essentially the most particular rule, it should disallow all the things underneath the /myaccount/ listing however permit solely the /myaccount/ web page to be crawled.
Right here’s one other use case of mixing the Disallow and Permit guidelines: in case you’ve your search underneath the /search/ listing and need it to be discovered and listed however block precise search URLs:
Person-agent: *
Disallow: /search/
Permit: /search/$
6. Block Non-Render Associated JavaScript Recordsdata
Each web site makes use of JavaScript, and lots of of those scripts aren’t associated to the rendering of content material, corresponding to monitoring scripts or these used for loading AdSense.
Googlebot can crawl and render a web site’s content material with out these scripts. Due to this fact, blocking them is protected and really helpful, because it saves requests and assets to fetch and parse them.
Beneath is a pattern line that’s disallowing pattern JavaScript, which comprises monitoring pixels.
Person-agent: *
Disallow: /property/js/pixels.js7. Block AI Chatbots And Scrapers
Many publishers are involved that their content material is being unfairly used to coach AI fashions with out their consent, they usually want to forestall this.
#ai chatbots
Person-agent: GPTBot
Person-agent: ChatGPT-Person
Person-agent: Claude-Net
Person-agent: ClaudeBot
Person-agent: anthropic-ai
Person-agent: cohere-ai
Person-agent: Bytespider
Person-agent: Google-Prolonged
Person-Agent: PerplexityBot
Person-agent: Applebot-Prolonged
Person-agent: Diffbot
Person-agent: PerplexityBot
Disallow: /#scrapers
Person-agent: Scrapy
Person-agent: magpie-crawler
Person-agent: CCBot
Person-Agent: omgili
Person-Agent: omgilibot
Person-agent: Node/simplecrawler
Disallow: /Right here, every consumer agent is listed individually, and the rule Disallow: / tells these bots to not crawl any a part of the positioning.
This, moreover stopping AI coaching in your content material, will help cut back the load in your server by minimizing pointless crawling.
For concepts on which bots to dam, you might wish to verify your server log information to see which crawlers are exhausting your servers, and keep in mind, robots.txt doesn’t forestall unauthorized entry.
8. Specify Sitemaps URLs
Together with your sitemap URL within the robots.txt file helps search engines like google and yahoo simply uncover all of the vital pages in your web site. That is executed by including a particular line that factors to your sitemap location, and you’ll specify a number of sitemaps, every by itself line.
Sitemap: https://www.instance.com/sitemap/articles.xml
Sitemap: https://www.instance.com/sitemap/information.xml
Sitemap: https://www.instance.com/sitemap/video.xmlIn contrast to Permit or Disallow guidelines, which permit solely a relative path, the Sitemap directive requires a full, absolute URL to point the placement of the sitemap.
Make sure the sitemaps’ URLs are accessible to search engines like google and yahoo and have correct syntax to keep away from errors.
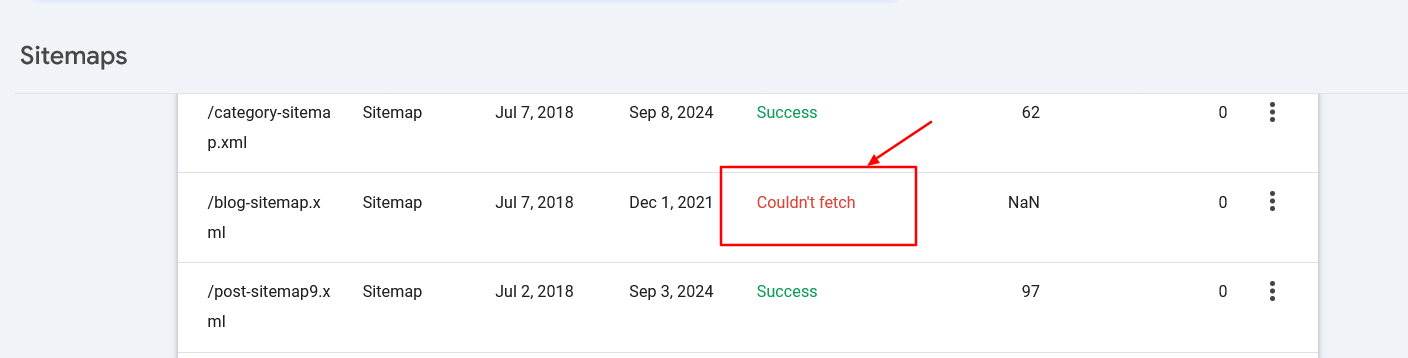 Sitemap fetch error in search console
Sitemap fetch error in search console9. When To Use Crawl-Delay
The crawl-delay directive in robots.txt specifies the variety of seconds a bot ought to wait earlier than crawling the following web page. Whereas Googlebot doesn’t acknowledge the crawl-delay directive, different bots might respect it.
It helps forestall server overload by controlling how regularly bots crawl your web site.
For instance, in order for you ClaudeBot to crawl your content material for AI coaching however wish to keep away from server overload, you possibly can set a crawl delay to handle the interval between requests.
Person-agent: ClaudeBot
Crawl-delay: 60This instructs the ClaudeBot consumer agent to attend 60 seconds between requests when crawling the web site.
In fact, there could also be AI bots that don’t respect crawl delay directives. In that case, you might want to make use of a internet firewall to price restrict them.
Troubleshooting Robots.txt
When you’ve composed your robots.txt, you need to use these instruments to troubleshoot if the syntax is appropriate or in case you didn’t unintentionally block an vital URL.
1. Google Search Console Robots.txt Validator
When you’ve up to date your robots.txt, it’s essential to verify whether or not it comprises any error or unintentionally blocks URLs you wish to be crawled, corresponding to assets, pictures, or web site sections.
Navigate Settings > robots.txt, and you will see that the built-in robots.txt validator. Beneath is the video of methods to fetch and validate your robots.txt.
2. Google Robots.txt Parser
This parser is official Google’s robots.txt parser which is utilized in Search Console.
It requires superior expertise to put in and run in your native pc. However it’s extremely really helpful to take time and do it as instructed on that web page as a result of you possibly can validate your adjustments within the robots.txt file earlier than importing to your server according to the official Google parser.
Centralized Robots.txt Administration
Every area and subdomain should have its personal robots.txt, as Googlebot doesn’t acknowledge root area robots.txt for a subdomain.
It creates challenges when you’ve a web site with a dozen subdomains, because it means you must preserve a bunch of robots.txt information individually.
Nevertheless, it’s potential to host a robots.txt file on a subdomain, corresponding to https://cdn.instance.com/robots.txt, and arrange a redirect from https://www.instance.com/robots.txt to it.
You are able to do vice versa and host it solely underneath the basis area and redirect from subdomains to the basis.
Serps will deal with the redirected file as if it had been positioned on the basis area. This method permits centralized administration of robots.txt guidelines for each your fundamental area and subdomains.
It helps make updates and upkeep extra environment friendly. In any other case, you would want to make use of a separate robots.txt file for every subdomain.
Conclusion
A correctly optimized robots.txt file is essential for managing a web site’s crawl price range. It ensures that search engines like google and yahoo like Googlebot spend their time on useful pages reasonably than losing assets on pointless ones.
However, blocking AI bots and scrapers utilizing robots.txt can considerably cut back server load and save computing assets.
Be sure you at all times validate your adjustments to keep away from surprising crawability points.
Nevertheless, do not forget that whereas blocking unimportant assets by way of robots.txt might assist enhance crawl effectivity, the primary elements affecting crawl price range are high-quality content material and web page loading pace.
Completely happy crawling!
Extra assets:
Featured Picture: BestForBest/Shutterstock