
{kind=link}
If you find yourself engaged on a knowledge science venture, the information is commonly tabular structured. You should utilize the built-in information desk to deal with such information in R. You can even use the well-known library dplyr as a substitute to profit from its wealthy toolset. On this publish, you’ll learn the way dplyr may help you discover and manipulate tabular information. Particularly, you’ll be taught:
- Methods to deal with a knowledge body
- Methods to carry out some frequent operations on a knowledge body
Let�s get began.

Exploring Knowledge utilizing dplyr in R.
Photograph by Airam Dato-on. Some rights reserved.
Overview
This publish is split into two components; they’re:
- Beginning wih dplyr
- Exploring a dataset
Beginning with dplyr
The library dplyr in R will be put in utilizing the command set up.bundle("dplyr") in R command line. However it’s normally useful to put in the tidyverse bundle as it’s a assortment of some helpful packages for information science:
|
set up.bundle(“tidyverse”) |
Earlier than you begin, you need to load the dplyr bundle, which can override some current R features and add new options:
The dplyr library is a strong information manipulation library. This library operates on tabular structured information known as information body. To create a knowledge body from scratch, you should utilize the next syntax:
|
df <– information.body( ��identify = c(“Alice”, “Bob”, “Charlie”), ��age = c(25, 30, 35), ��occupation = c(“Software program Engineer”, “Knowledge Scientist”, “Product Supervisor”) ) |
It offers features to control information frames, known as �verbs�. The verbs that function on rows of a single information body embody:
filter()selects rows by column valuesslice()selects rows by offsetprepare()kinds rows by values of a column
The verbs that function on columns of a knowledge body embody:
choose()picks a subset of columns.rename()modifications the identify of columns.mutate()modifications the values of columns and creates new columns.relocate()reorders of the columns.
As well as, you too can run group-by in the identical means as in SQL:
group_by()converts a desk right into a grouped deskungroup()expands a grouped desk right into a desksummarize()collapses a gaggle right into a single row.
Exploring a Dataset
Let�s try a dataset and see how dplyr may help us perceive the information.
The dataset you�re going to discover is the Boston housing dataset. You possibly can load this dataset from the Web:
|
boston_url <– ‘https://archive.ics.uci.edu/ml/machine-learning-databases/housing/housing.information’ Boston <– learn.desk(boston_url, col.identify=c(“crim”,“zn”,“indus”,“chas”,“nox”,“rm”,“age”,“dis”,“rad”,“tax”,“ptratio”,“black”,“lstat”,“medv”)) as_tibble(Boston) |
In R, this dataset can also be accessible as Boston from the MASS library:
|
library(MASS) as_tibble(Boston) |
In each circumstances, the operate as_tibble() is to wrap a knowledge body right into a �tibble� which permits a big desk to be displayed properly. The output of each can be as follows:
|
# A tibble: 506 � 14 ������crim����zn indus��chas�� nox����rm�� age�� dis�� rad�� tax ptratio black lstat��medv ���� <dbl> <dbl> <dbl> <int> <dbl> <dbl> <dbl> <dbl> <int> <dbl>�� <dbl> <dbl> <dbl> <dbl> 1 0.00632��18����2.31���� 0 0.538��6.58��65.2��4.09���� 1�� 296����15.3��397.��4.98��24�� 2 0.0273����0����7.07���� 0 0.469��6.42��78.9��4.97���� 2�� 242����17.8��397.��9.14��21.6 3 0.0273����0����7.07���� 0 0.469��7.18��61.1��4.97���� 2�� 242����17.8��393.��4.03��34.7 4 0.0324����0����2.18���� 0 0.458��7.00��45.8��6.06���� 3�� 222����18.7��395.��2.94��33.4 5 0.0690����0����2.18���� 0 0.458��7.15��54.2��6.06���� 3�� 222����18.7��397.��5.33��36.2 6 0.0298����0����2.18���� 0 0.458��6.43��58.7��6.06���� 3�� 222����18.7��394.��5.21��28.7 7 0.0883�� 12.5��7.87���� 0 0.524��6.01��66.6��5.56���� 5�� 311����15.2��396. 12.4�� 22.9 8 0.145����12.5��7.87���� 0 0.524��6.17��96.1��5.95���� 5�� 311����15.2��397. 19.2�� 27.1 9 0.211����12.5��7.87���� 0 0.524��5.63 100����6.08���� 5�� 311����15.2��387. 29.9�� 16.5 10 0.170����12.5��7.87���� 0 0.524��6.00��85.9��6.59���� 5�� 311����15.2��387. 17.1�� 18.9 # ? 496 extra rows # ? Use `print(n = …)` to see extra rows |
From this, you get some primary details about this dataset: There are 506 rows and 14 columns. The identify of every column are proven, in addition to their information sorts (they’re both double or integer on this case). You can even see the primary 10 rows of the information.
Nonetheless, chances are you’ll suppose this output remains to be fairly messy. In case you�re fascinated by solely a subset of columns, you should utilize the choose() operate, named after the identical operation in SQL:
|
choose(Boston, c(crim, medv)) |> as_tibble() |
The above is to take the information body Boston and choose solely the columns crim and medv, after which show it as a tibble (so we will make certain that the outcome would have the identical variety of rows as earlier than). The operator |> is a particular operator in R to imply that the output from the left is processed by the operate on the proper. That is equal to the next:
|
as_tibble(choose(Boston, c(crim, medv))) |
However the cause you discover it helpful might be that will help you take a look at your speculation. It is a housing market dataset. The crim column is the crime charge and medv is the median residence worth. You might marvel if the crime charge can predict the house worth. However intuitively, they need to be inversely correlated. So let�s plot the house worth towards the inverse of the crime charge:
|
Boston |> mutate( invcrim = 1/crim ) |> choose(c(invcrim, medv)) |> plot() |
Right here you used a number of |> operators to attach a number of operations. The mutate() operate may help you outline a brand new column (or modify an current one). The plot() operate expects a knowledge body with two columns, and it’ll produce a scatter plot. This line of code will produce the plot as follows:
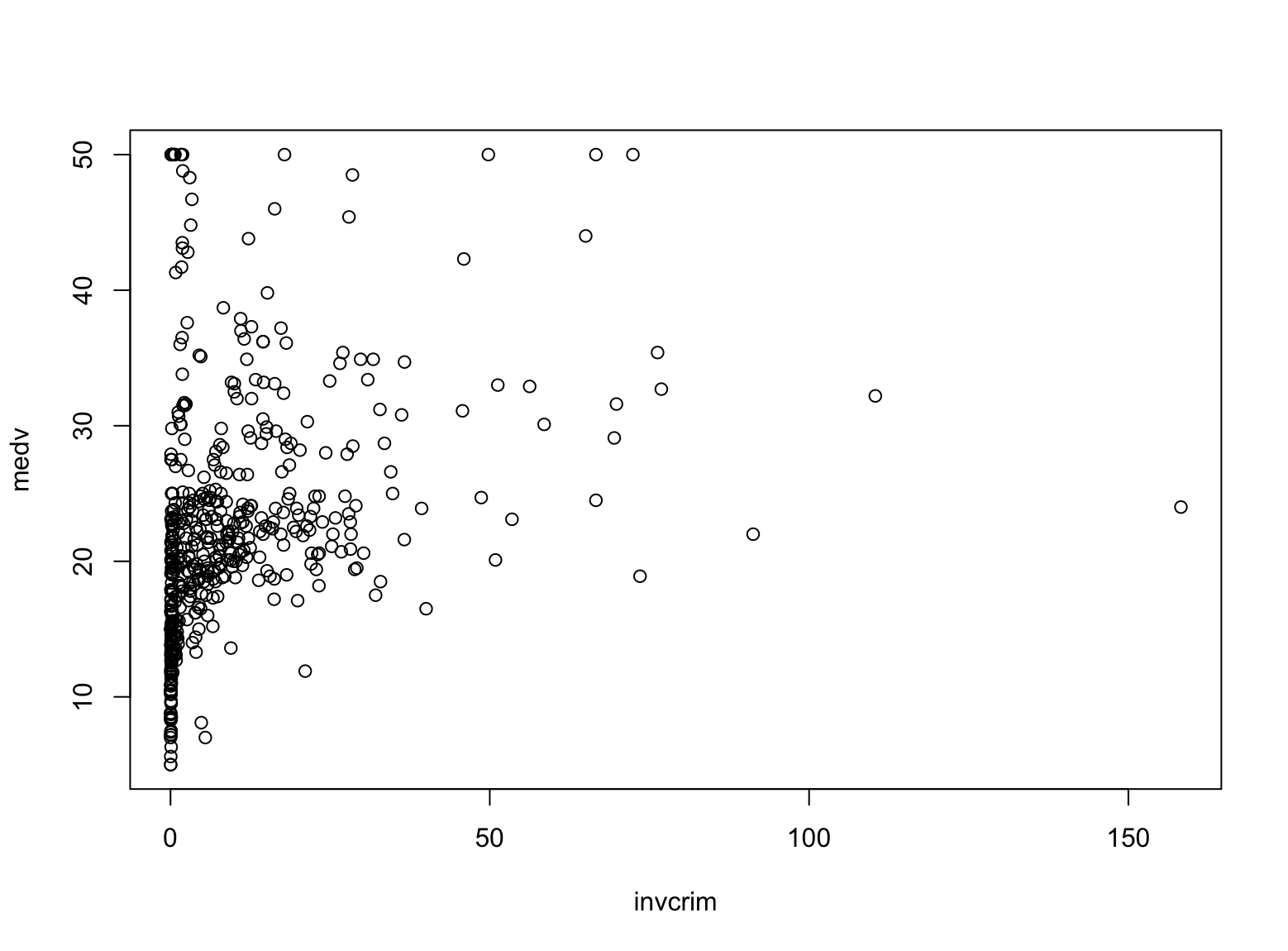
This doesn�t appear like to have a development. So you may additionally need to see if a section of the information can present a development. Let�s say, when you take solely the subset of age column better than 50. That�s what the filter() operate may help:
|
Boston |> filter(age > 50) |> choose(c(crim, medv)) |> plot() |
These are helpful instruments offered by dplyr. On this explicit dataset, the development just isn’t trivial to find on this ad-hoc means. You need to search for extra superior methods however these are the nice start line.
Apart from exploring information visually, you too can discover the information numerically. The best means of coping with information body is to make use of the abstract() operate:
This works for all numerical columns. You need to see the fundamental statistics of every columns, together with the utmost, minimal, median, imply, and so forth. Nonetheless, typically you need to see how totally different columns are correlated. For instance, the chas column on this dataset signifies whether or not the situation is close to Charles River. It has a worth of both 0 or 1. You possibly can inform how the house worth is expounded to such indicator variable utilizing group_by():
|
group_by(boston, chas) |> summarize(avg=imply(medv), sd=sd(medv)) |
The group_by() operate elevates a knowledge body into teams, which every group is a subset of rows with the identical worth within the chas column. Then the summarize() operate creates a brand new column with a worth computed from every group.
The output of the above is as follows:
|
# A tibble: 2 � 3 �� chas�� avg����sd ��<int> <dbl> <dbl> 1���� 0��22.1��8.83 2���� 1��28.4 11.8 |
In reality, the summarize() operate can be utilized with out group_by(), however that may apply to your entire information body; therefore the output will solely be one row.
Additional Readings
This part offers you some hyperlinks to review additional on the supplies above:
On-line supplies
Books:
Abstract
The library dplyr is a strong bundle for information manipulation. On this publish, you noticed how you should utilize it to filter, choose, and summarize information, and the way the instruments may help you discover a dataset. Particularly, you realized:
- Utilizing tibble as a special means of presenting abbrev
Photograph by Airam Dato-on. Some rights reserved.
iated information body
- Methods to manipulate tabular information by rows and columns
- Methods to carry out group-by operations and compute aggregated values in a knowledge body