
{kind=link}
Elasticsearch is an open-source, distributed JSON-based search and analytics engine constructed utilizing Apache Lucene with the aim of offering quick real-time search performance. It’s a NoSQL information retailer that’s document-oriented, scalable, and schemaless by default. Elasticsearch is designed to work at scale with massive information units. As a search engine, it offers quick indexing and search capabilities that may be horizontally scaled throughout a number of nodes.
Shameless plug: Rockset is a real-time indexing database within the cloud. It mechanically builds indexes which might be optimized not only for search but additionally aggregations and joins, making it quick and simple on your purposes to question information, no matter the place it comes from and what format it’s in. However this submit is about highlighting some workarounds, in case you actually wish to do SQL-style joins in Elasticsearch.
Why Do Knowledge Relationships Matter?
We reside in a extremely linked world the place dealing with information relationships is essential. Relational databases are good at dealing with relationships, however with continuously altering enterprise necessities, the mounted schema of those databases leads to scalability and efficiency points. The usage of NoSQL information shops is turning into more and more common as a consequence of their means to sort out a lot of challenges related to the standard information dealing with approaches.
Enterprises are regularly coping with complicated information buildings the place aggregations, joins, and filtering capabilities are required to investigate the info. With the explosion of unstructured information, there are a rising variety of use circumstances requiring the becoming a member of of information from totally different sources for information analytics functions.
Whereas joins are primarily an SQL idea, they’re equally essential within the NoSQL world as effectively. SQL-style joins usually are not supported in Elasticsearch as first-class residents. This text will focus on the best way to outline relationships in Elasticsearch utilizing varied strategies resembling denormalizing, application-side joins, nested paperwork, and parent-child relationships. It should additionally discover the use circumstances and challenges related to every strategy.
Learn how to Take care of Relationships in Elasticsearch
As a result of Elasticsearch is just not a relational database, joins don’t exist as a local performance like in an SQL database. It focuses extra on search effectivity versus storage effectivity. The saved information is virtually flattened out or denormalized to drive quick search use circumstances.
There are a number of methods to outline relationships in Elasticsearch. Based mostly in your use case, you may choose one of many beneath strategies in Elasticsearch to mannequin your information:
- One-to-one relationships: Object mapping
- One-to-many relationships: Nested paperwork and the parent-child mannequin
- Many-to-many relationships: Denormalizing and application-side joins
One-to-one object mappings are easy and won’t be mentioned a lot right here. The rest of this weblog will cowl the opposite two eventualities in additional element.
Need to study extra about Joins in Elasticsearch? Take a look at our submit on frequent use circumstances
Managing Your Knowledge Mannequin in Elasticsearch
There are 4 frequent approaches to managing information in Elasticsearch:
- Denormalization
- Utility-side joins
- Nested objects
- Guardian-child relationships
Denormalization
Denormalization offers the very best question search efficiency in Elasticsearch, since becoming a member of information units at question time isn�t obligatory. Every doc is impartial and incorporates all of the required information, thus eliminating the necessity for costly be part of operations.
With denormalization, the info is saved in a flattened construction on the time of indexing. Although this will increase the doc dimension and leads to the storage of duplicate information in every doc. Disk area is just not an costly commodity and thus little trigger for concern.
Use Circumstances for Denormalization
Whereas working with distributed methods, having to hitch information units throughout the community can introduce vital latencies. You possibly can keep away from these costly be part of operations by denormalizing information. Many-to-many relationships will be dealt with by information flattening.
Challenges with Knowledge Denormalization
- Duplication of information into flattened paperwork requires extra space for storing.
- Managing information in a flattened construction incurs extra overhead for information units which might be relational in nature.
- From a programming perspective, denormalization requires extra engineering overhead. You will have to write down extra code to flatten the info saved in a number of relational tables and map it to a single object in Elasticsearch.
- Denormalizing information is just not a good suggestion in case your information adjustments steadily. In such circumstances denormalization would require updating all the paperwork when any subset of the info had been to vary and so needs to be averted.
- The indexing operation takes longer with flattened information units since extra information is being listed. In case your information adjustments steadily, this is able to point out that your indexing price is larger, which might trigger cluster efficiency points.
Utility-Aspect Joins
Utility-side joins can be utilized when there’s a want to keep up the connection between paperwork. The information is saved in separate indices, and be part of operations will be carried out from the appliance facet throughout question time. This does, nonetheless, entail working extra queries at search time out of your software to hitch paperwork.
Use Circumstances for Utility-Aspect Joins
Utility-side joins make sure that information stays normalized. Modifications are executed in a single place, and there’s no must continuously replace your paperwork. Knowledge redundancy is minimized with this strategy. This technique works effectively when there are fewer paperwork and information adjustments are much less frequent.
Challenges with Utility-Aspect Joins
- The appliance must execute a number of queries to hitch paperwork at search time. If the info set has many customers, you will want to execute the identical set of queries a number of occasions, which might result in efficiency points. This strategy, due to this fact, doesn’t leverage the true energy of Elasticsearch.
- This strategy leads to complexity on the implementation degree. It requires writing extra code on the software degree to implement be part of operations to ascertain a relationship amongst paperwork.
Nested Objects
The nested strategy can be utilized if you must preserve the connection of every object within the array. Nested paperwork are internally saved as separate Lucene paperwork and will be joined at question time. They’re index-time joins, the place a number of Lucene paperwork are saved in a single block. From the appliance perspective, the block appears like a single Elasticsearch doc. Querying is due to this fact comparatively sooner, since all the info resides in the identical object. Nested paperwork take care of one-to-many relationships.
Use Circumstances for Nested Paperwork
Creating nested paperwork is most popular when your paperwork include arrays of objects. Determine 1 beneath exhibits how the nested sort in Elasticsearch permits arrays of objects to be internally listed as separate Lucene paperwork. Lucene has no idea of internal objects, therefore it’s fascinating to see how Elasticsearch internally transforms the unique doc into flattened multi-valued fields.
One benefit of utilizing nested queries is that it gained�t do cross-object matches, therefore surprising match outcomes are averted. It’s conscious of object boundaries, making the searches extra correct.

Determine 1: Arrays of objects listed internally as separate Lucene paperwork in Elasticsearch utilizing nested strategy
Challenges with Nested Objects
- The foundation object and its nested objects have to be fully reindexed with the intention to add/replace/delete a nested object. In different phrases, a toddler file replace will end in reindexing all the doc.
- Nested paperwork can’t be accessed instantly. They’ll solely be accessed by its associated root doc.
- Search requests return all the doc as a substitute of returning solely the nested paperwork that match the search question.
- In case your information set adjustments steadily, utilizing nested paperwork will end in numerous updates.
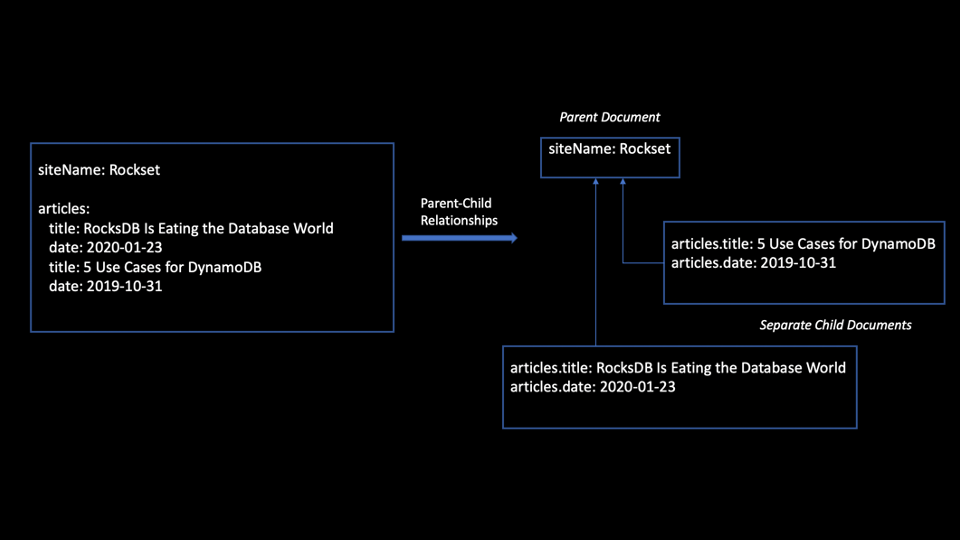
Guardian-Little one Relationships
Guardian-child relationships leverage the be part of datatype with the intention to fully separate objects with relationships into particular person paperwork�mother or father and little one. This allows you to retailer paperwork in a relational construction in separate Elasticsearch paperwork that may be up to date individually.
Guardian-child relationships are useful when the paperwork must be up to date usually. This strategy is due to this fact supreme for eventualities when the info adjustments steadily. Mainly, you separate out the bottom doc into a number of paperwork containing mother or father and little one. This enables each the mother or father and little one paperwork to be listed/up to date/deleted independently of each other.
Looking in Guardian and Little one Paperwork
To optimize Elasticsearch efficiency throughout indexing and looking out, the overall advice is to make sure that the doc dimension is just not massive. You possibly can leverage the parent-child mannequin to interrupt down your doc into separate paperwork.
Nevertheless, there are some challenges with implementing this. Guardian and little one paperwork must be routed to the identical shard in order that becoming a member of them throughout question time might be in-memory and environment friendly. The mother or father ID must be used because the routing worth for the kid doc. The _parent area offers Elasticsearch with the ID and kind of the mother or father doc, which internally lets it route the kid paperwork to the identical shard because the mother or father doc.
Elasticsearch lets you search from complicated JSON objects. This, nonetheless, requires an intensive understanding of the info construction to effectively question from it. The parent-child mannequin leverages a number of filters to simplify the search performance:
Returns mother or father paperwork which have little one paperwork matching the question.
Accepts a mother or father and returns little one paperwork that related dad and mom have matched.
Fetches related kids info from the has_child question.
Determine 2 exhibits how you should use the parent-child mannequin to exhibit one-to-many relationships. The kid paperwork will be added/eliminated/up to date with out impacting the mother or father. The identical holds true for the mother or father doc, which will be up to date with out reindexing the youngsters.

Determine 2: Guardian-child mannequin for one-to-many relationships
Challenges with Guardian-Little one Relationships
- Queries are costlier and memory-intensive due to the be part of operation.
- There may be an overhead to parent-child constructs, since they’re separate paperwork that have to be joined at question time.
- Want to make sure that the mother or father and all its kids exist on the identical shard.
- Storing paperwork with parent-child relationships includes implementation complexity.
Conclusion
Choosing the proper Elasticsearch information modeling design is important for software efficiency and maintainability. When designing your information mannequin in Elasticsearch, it is very important observe the assorted professionals and cons of every of the 4 modeling strategies mentioned herein.
On this article, we explored how nested objects and parent-child relationships allow SQL-like be part of operations in Elasticsearch. You can too implement customized logic in your software to deal with relationships with application-side joins. To be used circumstances through which you must be part of a number of information units in Elasticsearch, you may ingest and cargo each these information units into the Elasticsearch index to allow performant querying.
Out of the field, Elasticsearch doesn’t have joins as in an SQL database. Whereas there are potential workarounds for establishing relationships in your paperwork, it is very important pay attention to the challenges every of those approaches presents.

Utilizing Native SQL Joins with Rockset
When there’s a want to mix a number of information units for real-time analytics, a database that gives native SQL joins can deal with this use case higher. Like Elasticsearch, Rockset is used as an indexing layer on information from databases, occasion streams, and information lakes, allowing schemaless ingest from these sources. Not like Elasticsearch, Rockset offers the power to question with full-featured SQL, together with joins, supplying you with larger flexibility in how you should use your information.