

{kind=link}

Tim Berners-Lee�s legacy because the creator of the World Extensive Net is firmly cemented in historical past. However because the Web strayed away from its early egalitarian roots in direction of one thing far more large and company, Berners-Lee determined a radical new strategy to knowledge possession was wanted, which is why he co-founded an organization known as Inrupt.
As a substitute of getting your knowledge (i.e. knowledge about you) saved throughout an enormous array of various company databases, Berners-Lee theorized, what if every particular person could possibly be in control of his or her personal knowledge?
That’s the core concept behind Inrupt, the corporate that Berners-Lee co-founded in 2017 with tech exec John Bruce. Inrupt is the car by way of which the duo hope to unfold a brand new Web protocol, dubbed the Strong protocol, which facilitates distributed knowledge possession by and for the individuals.
The thought is radical in its simplicity, however has far-reaching implications, not only for making certain the privateness of information, but additionally to enhance the overall high quality of information for constructing AI, says David Ottenhimer, Inrupt�s vp of belief and digital ethics.
�Tim Berners-Lee had a imaginative and prescient of the Net, which he applied,� Ottenheimer tells Datanami. �After which he thought it wanted a course correction after time frame. Primarily the forces that be centralizing knowledge in direction of themselves had been the other of what we began with.�

(Picture supply: Inrupt)
When Berners-Lee wrote the primary proposal for the World Extensive Net in 1989, the Web was a a lot smaller and altruistic place than it’s now. Small teams of individuals, largely scientists, used the Web to share their work.
Because the Net grew extra commercialized, the static web sites of the Net 1.0 world had been now not ample for the challenges at hand, similar to the necessity to keep state for a purchasing cart on an e-commerce website. That kicked off the Net 2.0 period, characterised by extra JavaScript and APIs.
As Net corporations morphed into giants, they constructed big knowledge facilities to retailer huge quantities of consumer knowledge to work with their software. Berners-Lee�s perception is that it�s terribly inefficient to have a number of, duplicate monoliths of consumer knowledge that aren�t even that correct. The Net 3.0 period as an alternative will usher within the age of federated knowledge storage and federated entry.
Within the Net 3.0 world that Inrupt is attempting to construct, knowledge about every particular person is saved of their very personal private knowledge retailer, or a pod. These pods could be hosted by an organization or perhaps a authorities on behalf of their residents, similar to the federal government of Flanders is at the moment doing for its 6 million residents.
As a substitute requiring Net large to not lose or abuse billions of individuals�s knowledge, within the Inrupt scheme of issues, the person controls his or her personal knowledge by way of the pod. If a person desires to do enterprise with an organization on-line, they will grant entry to his her pod for a selected time frame, or simply for a selected sort of information. The corporate�s software then interacts with that knowledge, in a federated method, to ship no matter service it’s.
�So as an alternative of chasing 500 variations of you across the Net and attempting to say �Replace my handle, replace my identify, replace my no matter,� they arrive to you and it�s your knowledge they usually can see it one place,� Ottenheimer says.
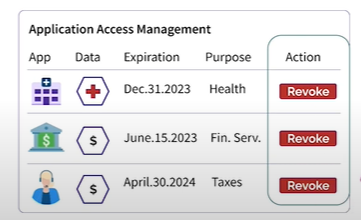
Customers can delete firm entry to their knowledge utilizing the Strong protocol (Picture supply: Inrupt)
At a technical stage, the pods are materialized as RDF shops. In keeping with Ottenheimer, customers can retailer any sort of information they need, not simply HTML pages. �Apps can write to the information retailer with any form of knowledge they will think about. It doesn�t must be a specific format,� he says. Whether or not it�s your poetry, the variety of chairs you’ve gotten in your house, your checking account information, or your healthcare report, it might probably all be saved, secured, and accessed by way of pods and the Strong protocol.
This strategy brings apparent advantages to the person, who’s now empowered to handle his or her personal knowledge and grant corporations� entry to it, if the deal is agreeable to them.� It�s additionally a pure answer for managing consent, which is a necessity on the planet of GDPR. Consent could be as granular because the consumer likes, they usually can cancel the consent at any time, very similar to they will merely flip off a bank card getting used to buy a service.
�The interoperability permits you to rotate to a different card. Get a brand new card, get a brand new quantity, so that you rotate your key and then you definately�re again to golden,� Ottenheimer says. �You [give consent] in a approach that is smart. You�re not giving it away without end, then discovering you possibly can now not get again the consent you gave years later and don’t know the place the consents are. We known as it the graveyard of previous consents.�
However this strategy additionally brings advantages to corporations, as a result of utilizing the W3C-sanctioned Strong protocol present a solution to decouple knowledge, purposes, and identities. Firms are also alleviated of the burden of getting to retailer and keep personal and delicate knowledge in accordance with GDPR, HIPAA and different guidelines.
Plus, it yields larger high quality knowledge, Ottenheimer says.
Inrupt�s Strong protocol could possibly be used for buyer 360 initiatives (Picture supply: Inrupt)
�It�s very thrilling as a result of queries are supposed to be agile, extra real-time, as they are saying,� he says. �I bear in mind this from very large retailers I labored with years in the past. You seize all this knowledge, you pull it in, after which there�s every kind of safety necessities to forestall breaches, so that you pull issues into different databases. Now they�re out of sync, typically stale. Seven days outdated is simply too outdated. And it�s unattainable to get a contemporary sufficient set of information that�s protected sufficient. There�s all these items conspiring in opposition to you to get question versus the pod mannequin, it�s inherently excessive efficiency, excessive scale, and prime quality.�
Firms could also be detest to surrender management of information. In any case, to turn into a �data-driven� firm, you kind of must be within the enterprise of storing, managing, and analyzing knowledge, proper? Effectively, Inrupt is attempting to show that assumption on its head.
In keeping with Ottenheimer, new tutorial analysis suggests that AI fashions constructed and operated in a federated mannequin atop remotely saved knowledge could outperform AI fashions constructed with a basic centrally managed datastore.
�The most recent analysis out of Oxford in truth exhibits that it�s larger velocity, larger efficiency if you distribute it,� he says. �In different phrases, for those who run AI fashions and federated the information, you get larger efficiency and better scale, than for those who attempt to pull every little thing central and run it.�
At first, the centrally managed knowledge set will outperform the federated one. In any case, the legal guidelines of physics do apply to knowledge, and geographic distance does add latency and complexity. However as updates to the information are required over time, the distributed mannequin will begin to outperform the centrally managed one, Ottenheimer says.
�At first, you�re going to get very quick outcomes for a really centralized, very giant knowledge set. You�ll be like, wow,� he says. �However then if you attempt to get larger and larger and larger, it falls over. And in reality, it will get inaccurate and that�s the place it actually will get scary, as a result of as soon as the integrity involves bear, then how do you clear it up?
�And you may�t clear up large knowledge units which can be actually sluggish,� he continues. �They turn into high heavy, and all people seems to be at them and says, I don�t perceive what�s occurring inside. I don�t know what�s unsuitable with them. Whereas when you have extremely distributed pod-based localized fashions and federated fashions utilizing federated studying, you possibly can clear it up.�![]()
For Ottenheiner, who has labored at various large knowledge companies through the years and breaks AI fashions for enjoyable, the thought of a smaller however larger high quality knowledge set brings sure benefits.
�That large knowledge factor that I labored on in 2012�that ship sailed,� he says. �We don�t need all the information on the planet as a result of it�s a bunch of rubbish. We wish actually good knowledge and we would like excessive efficiency by way of effectivity. We gained�t have knowledge facilities which can be the dimensions of Sunnyvale anymore that simply expend all of the vitality. We wish tremendous high-efficiency compute.�
The pod strategy might additionally pay dividends within the burgeoning world of generative AI. Presently, individuals predominantly are utilizing generalized fashions, similar to OpenAI�s ChatGPT or Amazon�s Alexa, which was just lately upgraded with GenAI capabilities. There’s a single foundational mannequin that�s been educated on a whole lot of thousands and thousands of previous interactions, together with the brand new ones that customers are having with it in the present day.
There many privateness and ethics challenges with GenAI. However with the pod mannequin of customized knowledge and customized fashions, customers could also be extra inclined to make use of the fashions, Ottenheimer says.
�So in a pod, you possibly can tune it, you possibly can prepare the mannequin to issues which can be related to you, and you’ll handle the protection of that knowledge, so that you get the confidentiality and also you get the integrity,� he says. �Let�s say for instance, you need it to unlearn one thing. Good luck [asking] Amazon�It�s such as you spilled ink into their water. Good luck getting that again out of their studying system in the event that they don�t plan forward for that form of drawback.
�Deleting the phrase I simply mentioned, in order that it doesn�t exist within the system, is unattainable until you begin over they usually�re not going to start out over on an enormous scale,� he continues. �But when they design it across the idea of a pod, after all you can begin over. Straightforward. Performed.�
Associated Objects:
AI Ethics Points Will Not Go Away
Privateness and Moral Hurdles to LLM Adoption Develop
Zoom Knowledge Debacle Shines Gentle on SaaS Knowledge Snooping
�
consent, Davi Ottenheimer, federated knowledge, federated studying, federated mannequin, pod, pod mannequin, Strong protocol, Tim Berners-Lee, W3C, Net 3.0