
Right this moment, we’re excited to announce that Unity Catalog Volumes is now usually accessible on AWS, Azure, and GCP. Unity Catalog gives a unified governance resolution for Knowledge and AI, natively constructed into the Databricks Knowledge Intelligence Platform. With Unity Catalog Volumes, Knowledge and AI groups can centrally catalog, safe, handle, share, and monitor lineage for any kind of non-tabular information, together with unstructured, semi-structured, and structured information, alongside tabular information and fashions.
On this weblog, we recap the core functionalities of Unity Catalog Volumes, present sensible examples of how they can be utilized to create scalable AI and ingestion purposes that contain loading information from varied file sorts and discover the enhancements launched with the GA launch.
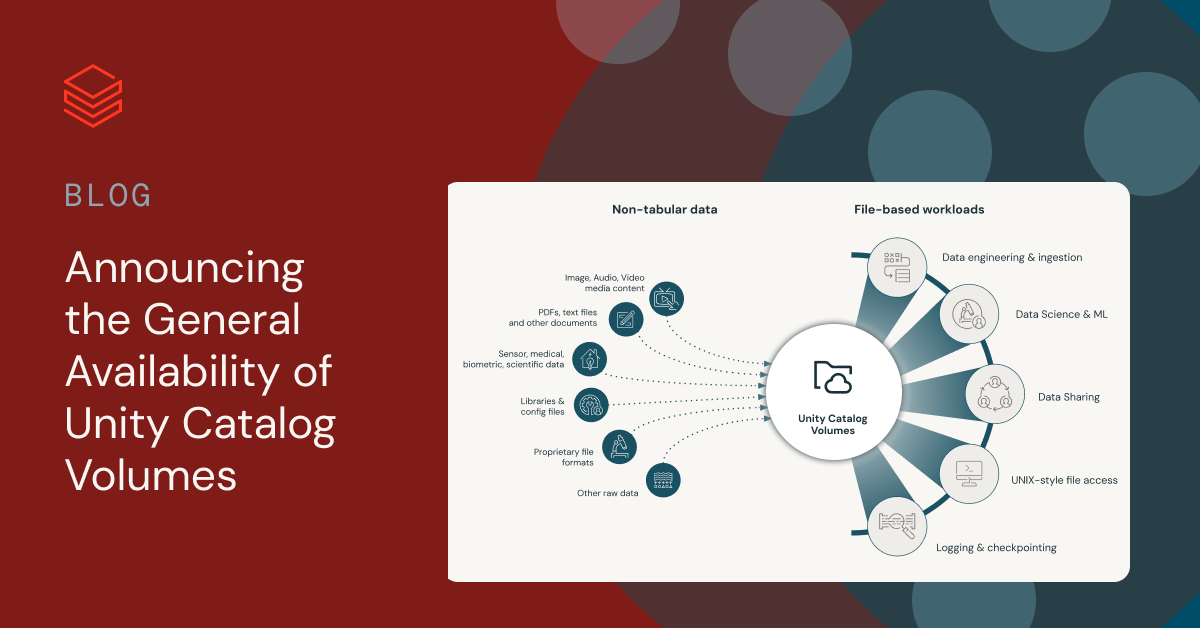
Managing non-tabular information with Unity Catalog Volumes
Volumes are a kind of object in Unity Catalog designed for the governance and administration of non-tabular information. Every Quantity is a set of directories and recordsdata in Unity Catalog, appearing as a logical storage unit in a Cloud object storage location. It gives capabilities for accessing, storing, and managing information in any format, whether or not structured, semi-structured, or unstructured.
Within the Lakehouse structure, purposes often begin by importing information from recordsdata. This includes studying directories, opening and studying present recordsdata, creating and writing new ones, in addition to processing file content material utilizing totally different instruments and libraries which can be particular to every use case.
With Volumes, you may create quite a lot of file-based purposes that learn and course of in depth collections of non-tabular information at cloud storage efficiency, no matter their format. Unity Catalog Volumes permits you to work with recordsdata utilizing your most popular instruments, together with Databricks workspace UIs, Spark APIs, Databricks file system utilities (dbutils.fs), REST APIs, language-native file libraries akin to Python’s os module, SQL connectors, the Databricks CLI, Databricks SDKs, Terraform, and extra.
“Within the journey to information democratization, streamlining the tooling accessible to customers is an important step. Unity Catalog Volumes allowed us to simplify how customers entry unstructured information, solely by way of Databricks Volumes. With Unity Catalog Volumes, we have been capable of substitute a fancy RBAC strategy to storage account entry in favor of a unified entry mannequin for structured and unstructured information with Unity Catalog. Customers have gone from many clicks and entry strategies to a single, direct entry mannequin that ensures a extra refined and easier to handle UX, each decreasing danger and hardening the general surroundings. ”
— Sergio Leoni, Head of Knowledge Engineering & Knowledge Platform, Plenitude
In our Public Preview weblog put up, we supplied an in depth overview of Volumes and the use instances they permit. In what follows, we exhibit the totally different capabilities of Volumes, together with new options accessible with the GA launch. We do that by showcasing two real-world eventualities that contain loading information from recordsdata. This step is important when constructing AI purposes or ingesting information.
Utilizing Volumes for AI purposes
AI purposes usually take care of giant quantities of non-tabular information akin to PDFs, pictures, movies, audio recordsdata, and different paperwork. That is significantly true for machine studying eventualities akin to pc imaginative and prescient and pure language processing. Generative AI purposes additionally fall underneath this class, the place strategies akin to Retrieval Augmented Era (RAG) are used to extract insights from non-tabular information sources. These insights are essential in powering chatbot interfaces, buyer assist purposes, content material creation, and extra.
Utilizing Volumes gives varied advantages to AI purposes, together with:
- Unified governance for tabular and non-tabular AI information units: All information concerned in AI purposes, be it non-tabular information managed by way of Volumes or tabular information, is now introduced collectively underneath the identical Unity Catalog umbrella.
- Finish-to-end lineage throughout AI purposes: The lineage of AI purposes now extends from the enterprise information base organized as Unity Catalog Volumes and tables, by way of information pipelines, mannequin fine-tuning and different customizations, all the best way to mannequin serving endpoints or endpoints internet hosting RAG chains in Generative AI. This permits for full traceability, auditability, and accelerated root-cause evaluation of AI purposes.
- Simplified developer expertise: Many AI libraries and frameworks don’t natively assist Cloud object storage APIs and as an alternative anticipate recordsdata on the native file system. Volumes’ built-in assist for FUSE permits customers to seamlessly leverage these libraries whereas working with recordsdata in acquainted methods.
- Streamlined syncing of AI utility responses to your supply information units: With options akin to Job file arrival triggers or Auto Loader’s file detection, now enhanced to assist Volumes, you may be sure that your AI utility responses are up-to-date by robotically updating them with the newest recordsdata added to a Quantity.
For example, let’s contemplate RAG purposes. When incorporating enterprise information into such an AI utility, one of many preliminary phases is to add and course of paperwork. This course of is simplified by utilizing Volumes. As soon as uncooked recordsdata are added to a Quantity, the supply information is damaged down into smaller chunks, transformed right into a numeric format by way of embedding, after which saved in a vector database. By utilizing Vector Search and Massive Language Fashions (LLMs), the RAG utility will thus present related responses when customers question the info.
In what follows, we exhibit the preliminary steps of making an RAG utility, ranging from a set of PDF recordsdata saved regionally on the pc. For the entire RAG utility, see the associated weblog put up and demo.
We begin by importing the PDF recordsdata compressed into a zipper file. For the sake of simplicity, we use the CLI to add the PDFs although comparable steps might be taken utilizing different instruments like REST APIs or the Databricks SDK. We start by itemizing the Quantity to determine the add vacation spot, then create a listing for our recordsdata, and at last, add the archive to this new listing:
databricks fs ls dbfs:/Volumes/main/default/my_volume
databricks fs mkdir dbfs:/Volumes/main/default/my_volume/uploaded_pdfs
databricks fs cp upload_pdfs.zip dbfs:/Volumes/main/default/my_volume/uploaded_pdfs/Now, we unzip the archive from a Databricks pocket book. Given Volumes’ built-in FUSE assist, we will run the command immediately the place the recordsdata are situated contained in the Quantity:
%sh
cd /Volumes/primary/default/my_volume
unzip upload_pdfs.zip -d uploaded_pdfs
ls uploaded_pdfsUtilizing Python UDFs, we extract the PDF textual content, chunk it, and create embeddings. The gen_chunks UDF takes a Quantity path and outputs textual content chunks. The gen_embedding UDF processes a textual content chunk to return a vector embedding.
%python
@udf('array<string>')
def gen_chunks(path: str) -> listing[str]:
from pdfminer.high_level import extract_text
from langchain.text_splitter import TokenTextSplitter
textual content = extract_text(path)
splitter = TokenTextSplitter(chunk_size = 500, chunk_overlap = 50)
return [doc.page_content for doc in splitter.create_documents([text])]
@udf
def gen_embedding(chunk: str) -> listing[float]:
import mlflow.deployments
deploy_client = mlflow.deployments.get_deploy_client("databricks")
response = deploy_client.predict(endpoint="databricks-bge-large-en", inputs={"enter": [chunk]})
return response.information[0]['embedding']We then use the UDFs together with Auto Loader to load the chunks right into a Delta desk, as proven under. This Delta desk have to be linked with a Vector Search index, a vital part of a RAG utility. For brevity, we refer the reader to a associated tutorial for the steps required to configure the index.
%python
from pyspark.sql.capabilities import explode
df = (spark.readStream
.format('cloudFiles')
.choice('cloudFiles.format', 'BINARYFILE')
.load("/Volumes/primary/default/my_volume/uploaded_pdfs")
.choose(
'_metadata',
explode(gen_chunks('_metadata.file_path')).alias('chunk'),
gen_embedding('chunk').alias('embedding'))
)
(df.writeStream
.set off(availableNow=True)
.choice("checkpointLocation", '/Volumes/primary/default/my_volume/checkpoints/pdfs_example')
.desk('primary.default.pdf_embeddings')
.awaitTermination()
)In a manufacturing setting, RAG purposes usually depend on in depth information bases of non-tabular information which can be continuously altering. Thus, it’s essential to automate the replace of the Vector Search index with the newest information to maintain utility responses present and stop any information duplication. To attain this, we will create a Databricks Workflows pipeline that automates the processing of supply recordsdata utilizing code logic, as beforehand described. If we moreover configure the Quantity as a monitored location for file arrival triggers, the pipeline will robotically course of new recordsdata as soon as added to a Quantity. Numerous strategies can be utilized to commonly add these recordsdata, akin to CLI instructions, the UI, REST APIs, or SDKs.
Except for inner information, enterprises might also leverage externally provisioned information, akin to curated datasets or information bought from companions and distributors. By utilizing Quantity Sharing, you may incorporate such datasets into RAG purposes with out first having to repeat the info. Take a look at the demo under to see Quantity Sharing in motion.
Utilizing Volumes in the beginning of your ingestion pipelines
Within the earlier part, we demonstrated find out how to load information from unstructured file codecs saved in a Quantity. You possibly can simply as properly use Volumes for loading information from semi-structured codecs like JSON or CSV or structured codecs like Parquet, which is a standard first step throughout ingestion and ETL duties.
You need to use Volumes to load information right into a desk utilizing your most popular ingestion instruments, together with Auto Loader, Delta Stay Tables (DLT), COPY INTO, or by working CTAS instructions. Moreover, you may be sure that your tables are up to date robotically when new recordsdata are added to a Quantity by leveraging options akin to Job file arrival triggers or Auto Loader file detection. Ingestion workloads involving Volumes might be executed from the Databricks workspace or an SQL connector.
Listed here are just a few examples of utilizing Volumes in CTAS, COPY INTO, and DLT instructions. Utilizing Auto Loader is sort of just like the code samples we lined within the earlier part.
CREATE TABLE demo.ingestion.table_raw AS
SELECT * FROM json.`/Volumes/demo/ingestion/raw_data/json/`COPY INTO demo.ingestion.table_raw FROM '/Volumes/demo/ingestion/raw_data/json/'CREATE STREAMING LIVE TABLE table_raw AS
SELECT * FROM STREAM read_files("/Volumes/demo/ingestion/raw_data/json/")You may also shortly load information from Volumes right into a desk from the UI utilizing our newly launched desk creation wizard for Volumes. That is particularly useful for ad-hoc information science duties if you need to create a desk shortly utilizing the UI without having to write down any code. The method is demonstrated within the screenshot under.

{kind=link}
Unity Catalog Volumes GA Launch in a Nutshell
The final availability launch of Volumes consists of a number of new options and enhancements, a few of which have been demonstrated within the earlier part. Summarized, the GA launch consists of:
- Quantity Sharing with Delta Sharing and Volumes within the Databricks Market: Now, you may share Volumes by way of Delta Sharing. This permits prospects to securely share in depth collections of non-tabular information, akin to PDFs, pictures, movies, audio recordsdata, and different paperwork and property, together with tables, notebooks, and AI fashions, throughout clouds, areas, and accounts. It additionally simplifies collaboration between enterprise models or companions, in addition to the onboarding of recent collaborators. Moreover, prospects can leverage Volumes sharing in Databricks Market, making it simple for information suppliers to share any non-tabular information with information customers. Quantity Sharing is now in Public Preview throughout AWS, Azure, and GCP.
- File administration utilizing instrument of your alternative: You possibly can run file administration operations akin to importing, downloading, deleting, managing directories, or itemizing recordsdata utilizing the Databricks CLI (AWS | Azure | GCP), the Recordsdata REST API (AWS | Azure | GCP) – now in Public Preview, and the Databricks SDKs for (AWS | Azure | GCP). Moreover, the Python, Go, Node.js, and JDBC Databricks SQL connectors present the PUT, GET, and REMOVE SQL instructions that enable for the importing, downloading, and deleting of recordsdata saved in a Quantity (AWS | Azure | GCP), with assist for ODBC coming quickly.
- Volumes assist in Scala and Python UDFs and Scala IO: Now you can entry Quantity paths from UDFs and execute IO operations in Scala throughout all compute entry modes (AWS | Azure | GCP).
- Job file arrival triggers assist for Volumes: Now you can configure Job file arrival triggers for storage accessed by way of Volumes (AWS | Azure | GCP), a handy method to set off advanced pipelines when new recordsdata are added to a Quantity.
- Entry recordsdata utilizing Cloud storage URIs: Now you can entry information in exterior Volumes utilizing Cloud storage URIs, along with the Databricks Quantity paths (AWS | Azure | GCP). This makes it simpler to make use of present code if you get began in adopting Volumes.
- Cluster libraries, job dependencies, and init scripts assist for Volumes: Volumes at the moment are supported as a supply for cluster libraries, job dependencies, and init scripts from each the UI and APIs. Seek advice from this associated weblog put up for extra particulars.
- Discovery Tags. Now you can outline and handle Quantity-level tagging utilizing the UI, SQL instructions, and knowledge schema (AWS | Azure | GCP).
- Enhancements of the Volumes UI. The Volumes UI has been upgraded to assist varied file administration operations, together with creating tables from recordsdata and downloading and deleting a number of recordsdata directly. We’ve additionally elevated the utmost file dimension for uploads and downloads from 2 GB to five GB.
Getting Began with Volumes
To get began with Volumes, comply with our complete step-by-step information for a fast tour of the important thing Quantity options. Seek advice from our documentation for detailed directions on creating your first Quantity (AWS | Azure | GCP). As soon as you’ve got created a Quantity, you may leverage the Catalog Explorer (AWS | Azure | GCP) to discover its contents, use the SQL syntax for Quantity administration (AWS | Azure | GCP), or share Volumes with different collaborators (AWS | Azure | GCP). We additionally encourage you to assessment our greatest practices (AWS | Azure | GCP) to take advantage of out of your Volumes.