

{kind=link}
Right now, Confluent introduced the final availability of its serverless Apache Flink service. Flink is likely one of the hottest stream processing applied sciences, ranked as a prime 5 Apache undertaking and backed by a various committer group together with Alibaba and Apple. It powers steam processing at many firms together with Uber, Netflix, and Linkedin.
Rockset clients utilizing Flink typically share how difficult it’s to self-manage Flink for streaming transformations. That’s why we’re thrilled that Confluent Cloud is making it simpler to make use of Flink, offering environment friendly and performant stream processing whereas saving engineers from complicated infrastructure administration.
Whereas it is well-known that Flink excels at filtering, becoming a member of and enriching streaming knowledge from Apache Kafka® or Confluent Cloud, what’s much less identified is that it’s more and more turning into ingrained within the end-to-end stack for AI-powered functions. That’s as a result of efficiently deploying an AI utility requires retrieval augmented era or “RAG” pipelines, processing real-time knowledge streams, chunking knowledge, producing embeddings, storing embeddings and operating vector search.
On this weblog, we’ll talk about how RAG matches into the paradigm of real-time knowledge processing and present an instance product advice utility utilizing each Kafka and Flink on Confluent Cloud along with Rockset.
What’s RAG?
LLMs like ChatGPT are educated on huge quantities of textual content knowledge out there as much as a cutoff date. As an illustration, GPT-4’s cutoff date was April 2023, so it could not pay attention to any occasions or developments occurring past that time of time. Moreover, whereas LLMs are educated on a big corpus of textual content knowledge, they aren’t educated to the specifics of a website, use case or possess inside firm information. This information is what offers many functions their relevance, producing extra correct responses.
LLMs are additionally liable to hallucinations, or making up inaccurate responses. By grounding responses in retrieval info, LLMs can draw on dependable knowledge for his or her response as an alternative of solely counting on their pre-existing information base.
Constructing a real-time, contextual and reliable information base for AI functions revolves round RAG pipelines. These pipelines take contextual knowledge and feed it into an LLM to enhance the relevancy of a response. Let’s check out every step in a RAG pipeline within the context of constructing a product advice engine:
- Streaming knowledge: An internet product catalog like Amazon has knowledge on completely different merchandise like identify, maker, description, value, consumer suggestions, and so on. The web catalog expands as new objects are added or updates are made akin to new pricing, availability, suggestions and extra.
- Chunking knowledge: Chunking is breaking down giant textual content information into extra manageable segments to make sure probably the most related chunk of knowledge is handed to the LLM. For an instance product catalog, a piece will be the concatenation of the product identify, description and a single advice.
- Producing vector embeddings: Creating vector embeddings entails reworking chunks of textual content into numerical vectors. These vectors seize the underlying semantics and contextual relationships of the textual content in a multidimensional area.
- Indexing vectors: Indexing algorithms may also help to go looking throughout billions of vectors shortly and effectively. Because the product catalog is continually being added to, producing new embeddings and indexing them occurs in actual time.
- Vector search: Discover probably the most related vectors primarily based on the search question in millisecond response occasions. For instance, a consumer could also be looking “Area Wars” in a product catalog and on the lookout for different comparable online game suggestions.
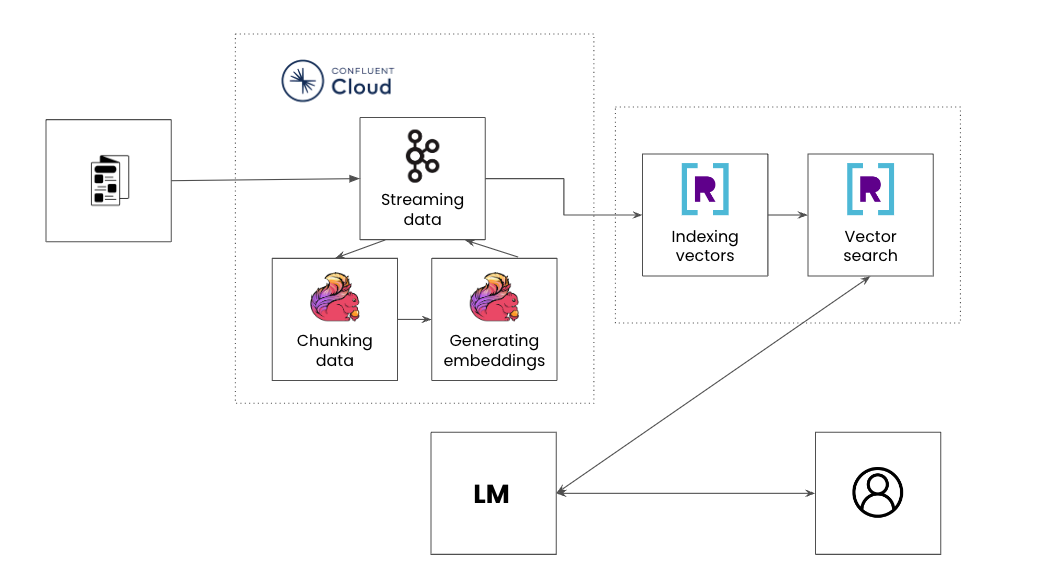
Whereas a RAG pipeline captures the particular steps to construct AI functions, these steps resemble a standard stream processing pipeline the place knowledge is streamed from a number of sources, enriched and served to downstream functions. AI-powered functions even have the identical set of necessities as another user-facing utility, its backend companies should be dependable, performant and scalable.
What are the challenges constructing RAG pipelines?
Streaming-first architectures are a obligatory basis for the AI period. A product suggestions utility is way more related if it might probably incorporate indicators about what merchandise are in inventory or could be shipped inside 48 hours. If you find yourself constructing functions for constant, real-time efficiency at scale it would be best to use a streaming-first structure.
There are a number of challenges that emerge when constructing real-time RAG pipelines:
- Actual-time supply of embeddings & updates
- Actual-time metadata filtering
- Scale and effectivity for real-time knowledge
Within the following sections, we’ll talk about these challenges broadly and delve into how they apply extra particularly to vector search and vector databases.
Actual-time supply of embeddings and updates
Quick suggestions on contemporary knowledge require the RAG pipeline to be designed for streaming knowledge. Additionally they should be designed for real-time updates. For a product catalog, the latest objects must have embeddings generated and added to the index.
Indexing algorithms for vectors don’t natively assist updates nicely. That’s as a result of the indexing algorithms are fastidiously organized for quick lookups and makes an attempt to incrementally replace them with new vectors quickly deteriorate the quick lookup properties. There are various potential approaches {that a} vector database can use to assist with incremental updates- naive updating of vectors, periodic reindexing, and so on. Every technique has ramifications for the way shortly new vectors can seem in search outcomes.
Actual-time metadata filtering
Streaming knowledge on merchandise in a catalog is used to generate vector embeddings in addition to present further contextual info. For instance, a product advice engine might need to present comparable merchandise to the final product a consumer searched (vector search) which are extremely rated (structured search) and out there for transport with Prime (structured search). These further inputs are known as metadata filtering.
Indexing algorithms are designed to be giant, static and monolithic making it troublesome to run queries that be a part of vectors and metadata effectively. The optimum strategy is single-stage metadata filtering that merges filtering with vector lookups. Doing this successfully requires each the metadata and the vectors to be in the identical database, leveraging question optimizations to drive quick response occasions. Nearly all AI functions will need to embody metadata, particularly real-time metadata. How helpful would your product advice engine be if the merchandise beneficial was out of inventory?
Scale and effectivity for real-time knowledge
AI functions can get very costly in a short time. Producing vector embeddings and operating vector indexing are each compute-intensive processes. The flexibility of the underlying structure to assist streaming knowledge for predictable efficiency, in addition to scale up and down on demand, will assist engineers proceed to leverage AI.
In lots of vector databases, indexing of vectors and search occur on the identical compute clusters for quicker knowledge entry. The draw back of this tightly coupled structure, typically seen in methods like Elasticsearch, is that it can lead to compute competition and provisioning of assets for peak capability. Ideally, vector search and indexing occur in isolation whereas nonetheless accessing the identical real-time dataset.
Why use Confluent Cloud for Apache Flink and Rockset for RAG?
Confluent Cloud for Apache Flink and Rockset, the search and analytics database constructed for the cloud, are designed to assist high-velocity knowledge, real-time processing and disaggregation for scalability and resilience to failures.
Listed here are the advantages of utilizing Confluent Cloud for Apache Flink and Rockset for RAG pipelines:
- Assist high-velocity stream processing and incremental updates: Incorporate real-time insights to enhance the relevance of AI functions. Rockset is a mutable database, effectively updating metadata and indexes in actual time.
- Enrich your RAG pipeline with filters and joins: Use Flink to counterpoint the pipeline, producing real-time embeddings, chunking knowledge and guaranteeing knowledge safety and privateness. Rockset treats metadata filtering as a first-class citizen, enabling SQL over vectors, textual content, JSON, geo and time collection knowledge.
- Construct for scale and developer velocity: Scale up and down on demand with cloud-native companies which are constructed for effectivity and elasticity. Rockset isolates indexing compute from question compute for predictable efficiency at scale.
Structure for AI-powered Suggestions
Let’s now have a look at how we are able to leverage Kafka and Flink on Confluent Cloud with Rockset to construct a real-time RAG pipeline for an AI-powered suggestions engine.
For this instance AI-powered advice utility, we’ll use a publicly out there Amazon product opinions dataset that features product opinions and related metadata together with product names, options, costs, classes and descriptions.
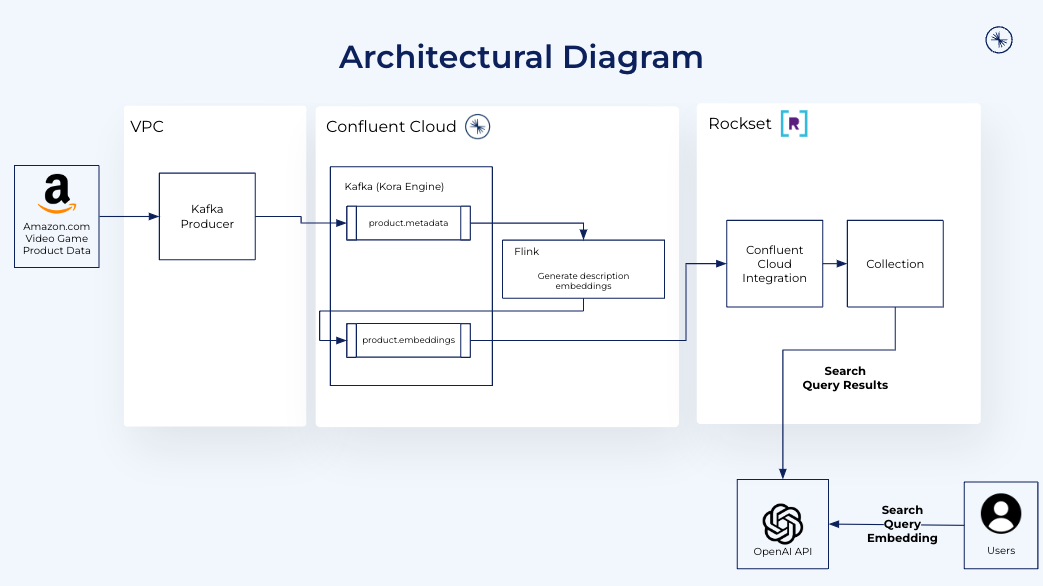
We’ll discover probably the most comparable video video games to Starfield which are suitable with the Ps console. Starfield is a well-liked online game on Xbox and players utilizing Ps might need to discover comparable video games that work with their setup. We’ll use Kafka to stream product opinions, Flink to generate product embeddings and Rockset to index the embeddings and metadata for vector search.
Confluent Cloud
Confluent Cloud is a fully-managed knowledge streaming platform that may stream vectors and metadata from wherever the supply knowledge resides, offering easy-to-use native connectors. Its managed service from the creators of Apache Kafka gives elastic scalability, assured resiliency with a 99.99% uptime SLA and predictable low latency.
We setup a Kafka producer to publish occasions to a Kafka cluster. The producer ingests Amazon.com product catalog knowledge in actual time and sends it to Confluent Cloud. It runs java utilizing docker compose to create the Kafka producer and Apache Flink.
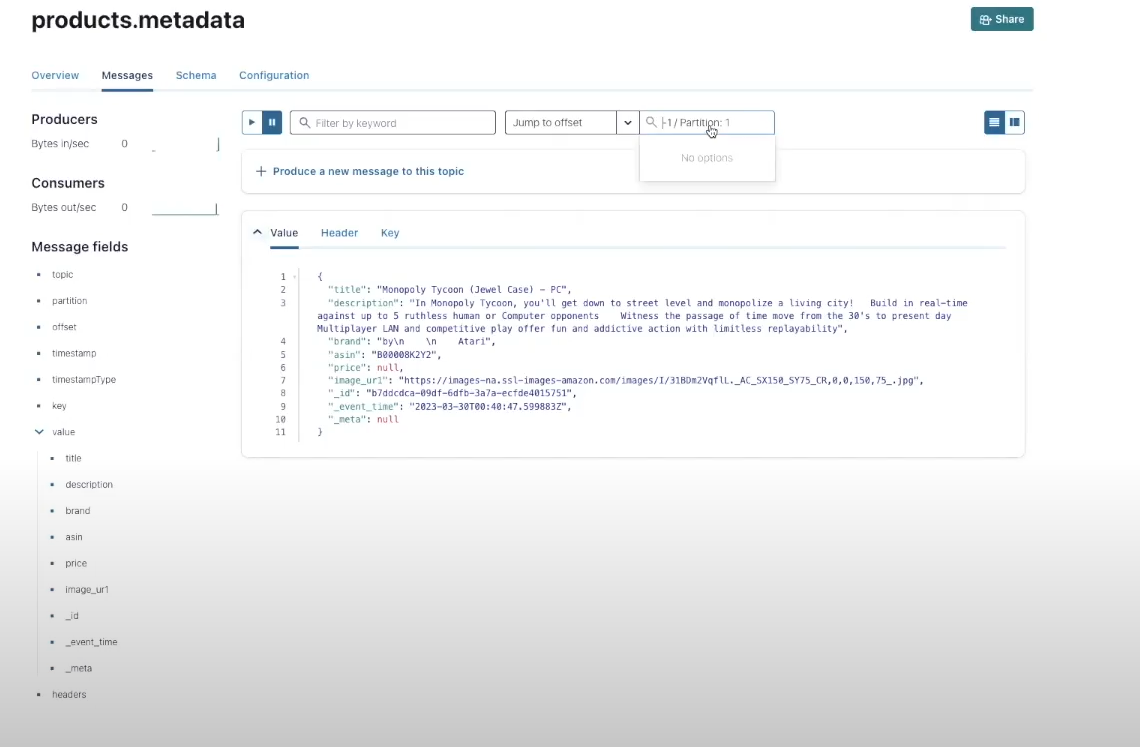
In Confluent Cloud, we create a cluster for the AI-powered product suggestions with the subject of product.metadata.
Apache Flink for Confluent Coud
Simply filter, be a part of and enrich the Confluent knowledge stream with Flink, the de facto customary for stream processing, now out there as a serverless, fully-managed resolution on Confluent Cloud. Expertise Kafka and Flink collectively as a unified platform, with absolutely built-in monitoring, safety and governance.
To course of the merchandise.metadata and generate vector embeddings on the fly we use Flink on Confluent Cloud. Throughout stream processing, every product overview is consumed one-by-one, overview textual content is extracted and despatched to OpenAI to generate vector embeddings and vector embeddings are connected as occasions to a newly created merchandise.embeddings subject. As we don’t have an embedding algorithm in-house for this instance, we now have to create a user-defined perform to name out to OpenAI and generate the embeddings utilizing self-managed Flink.
We are able to return to the Confluent console and discover the merchandise.embeddings subject created utilizing Flink and OpenAI.
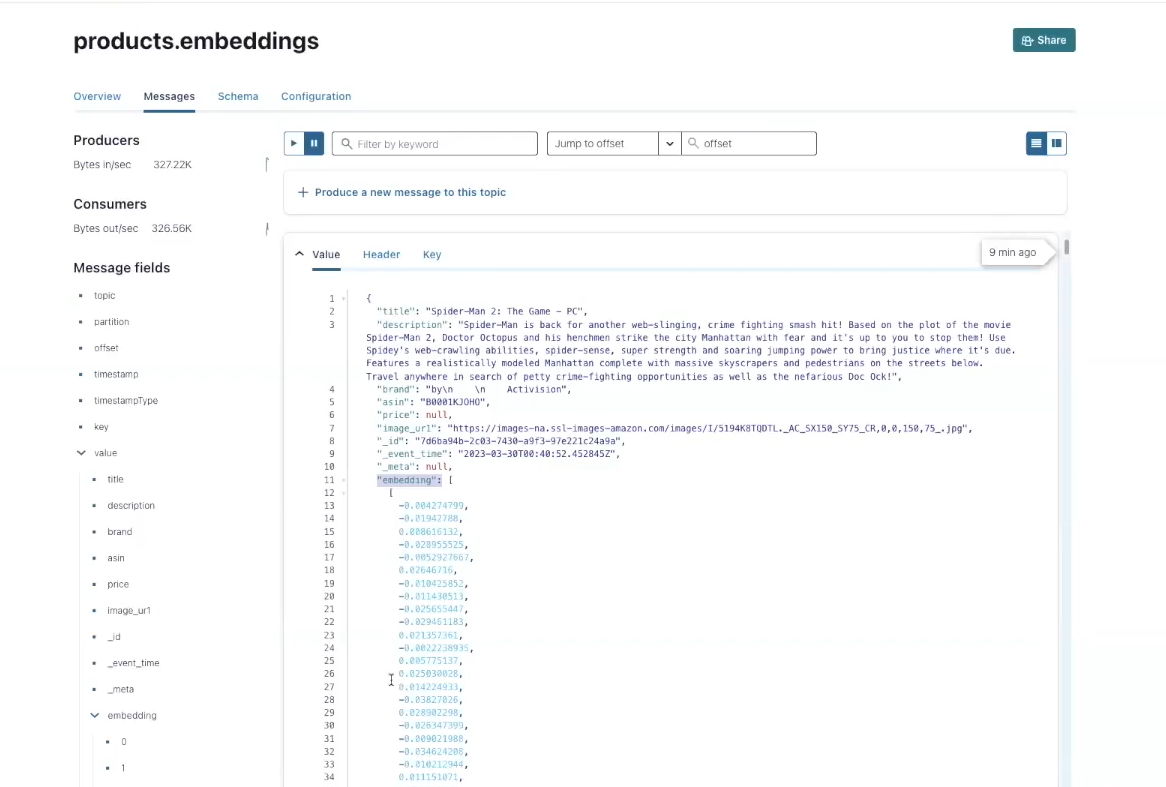
Rockset
Rockset is the search and analytics database constructed for the cloud with a local integration to Kafka for Confluent Cloud. With Rockset’s cloud-native structure, indexing and vector search happen in isolation for environment friendly, predictable efficiency. Rockset is constructed on RocksDB and helps incremental updating of vector indexes effectively. Its indexing algorithms are primarily based on the FAISS library, a library that’s well-known for its assist of updates.
Rockset acts as a sink for Confluent Cloud, selecting up streaming knowledge from the product.embeddings subject and indexing it for vector search.
On the time a search question is made, ie “discover me all the same embeddings to time period “area wars” which are suitable with Ps and under $50,” the applying makes a name to OpenAI to show the search time period “area wars” right into a vector embedding after which finds probably the most comparable merchandise within the Amazon catalog utilizing Rockset as a vector database. Rockset makes use of SQL as its question language, making metadata filtering as simple as a SQL WHERE clause.
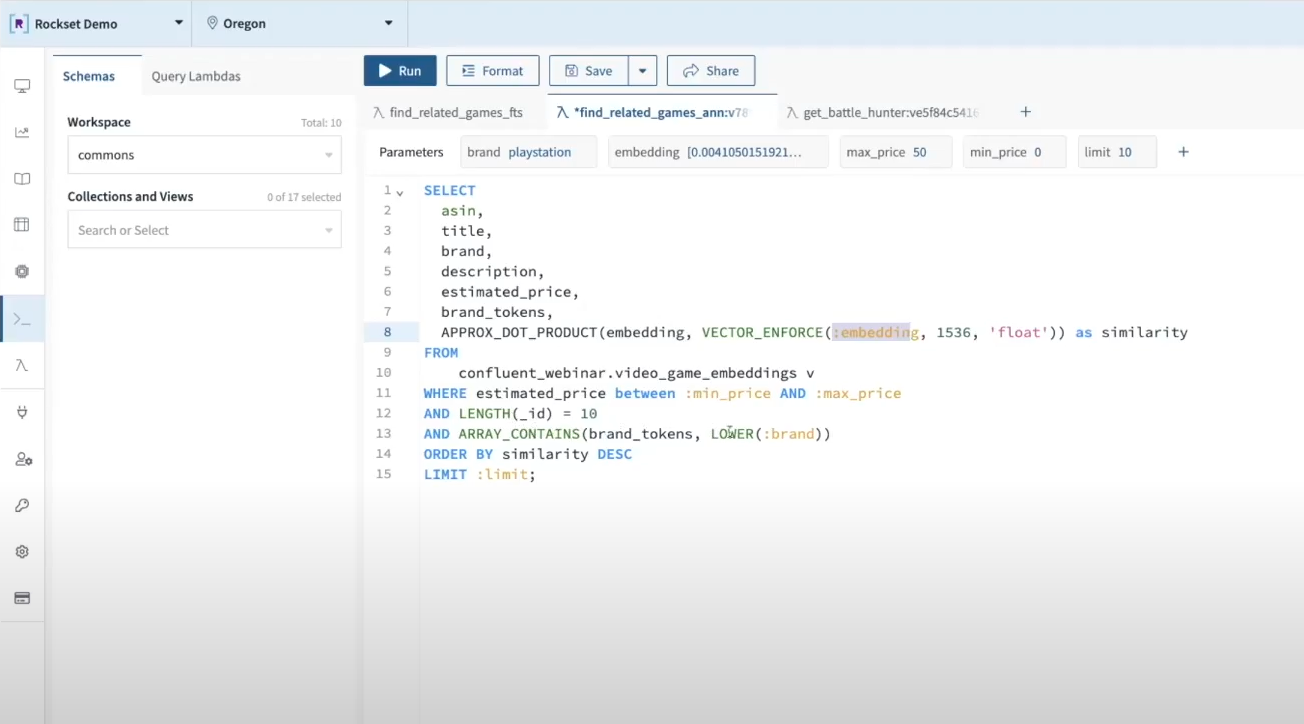
Cloud-native stack for AI-powered functions on streaming knowledge
Confluent’s serverless Flink providing completes the end-to-end cloud stack for AI-powered functions. Engineering groups can now give attention to constructing subsequent era AI functions somewhat than managing infrastructure. The underlying cloud companies scale up and down on demand, guaranteeing predictable efficiency with out the expensive overprovisioning of assets.
As we walked via on this weblog, RAG pipelines profit from real-time streaming architectures, seeing enhancements within the relevance and trustworthiness of AI functions. When designing for real-time RAG pipelines the underlying stack ought to assist streaming knowledge, updates and metadata filtering as first-class residents.
Constructing AI-applications on streaming knowledge has by no means been simpler. We walked via the fundamentals of constructing an AI-powered product advice engine on this weblog. You possibly can reproduce these steps utilizing the code discovered on this GitHub repository. Get began constructing your individual utility at this time with free trials of Confluent Cloud and [Rockset].
Embedded content material: https://youtu.be/mvkQjTIlc-c?si=qPGuMtCOzq9rUJHx
Notice: The Amazon Assessment dataset was taken from: Justifying suggestions utilizing distantly-labeled opinions and fine-grained features Jianmo Ni, Jiacheng Li, Julian McAuley Empirical Strategies in Pure Language Processing (EMNLP), 2019. It incorporates precise merchandise however they’re just a few years previous