

{kind=link}
Scientific ink is a set of software program utilized in over a thousand scientific trials to streamline the info assortment and administration course of, with the purpose of enhancing the effectivity and accuracy of trials. Its cloud-based digital information seize system allows scientific trial information from greater than 2 million sufferers throughout 110 international locations to be collected electronically in real-time from a wide range of sources, together with digital well being information and wearable gadgets.
With the COVID-19 pandemic forcing many scientific trials to go digital, Scientific ink has been an more and more worthwhile resolution for its skill to assist distant monitoring and digital scientific trials. Moderately than require trial contributors to come back onsite to report affected person outcomes they’ll shift their monitoring to the house. Consequently, trials take much less time to design, develop and deploy and affected person enrollment and retention will increase.
To successfully analyze information from scientific trials within the new remote-first atmosphere, scientific trial sponsors got here to Scientific ink with the requirement for a real-time 360-degree view of sufferers and their outcomes throughout your complete international examine. With a centralized real-time analytics dashboard geared up with filter capabilities, scientific groups can take speedy motion on affected person questions and opinions to make sure the success of the trial. The 360-degree view was designed to be the info epicenter for scientific groups, offering a birds-eye view and sturdy drill down capabilities so scientific groups may hold trials on monitor throughout all geographies.
When the necessities for the brand new real-time examine participant monitoring got here to the engineering group, I knew that the present technical stack couldn’t assist millisecond-latency complicated analytics on real-time information. Amazon OpenSearch, a fork of Elasticsearch used for our utility search, was quick however not purpose-built for complicated analytics together with joins. Snowflake, the sturdy cloud information warehouse utilized by our analyst group for performant enterprise intelligence workloads, noticed important information delays and couldn’t meet the efficiency necessities of the appliance. This despatched us to the drafting board to give you a brand new structure; one which helps real-time ingest and sophisticated analytics whereas being resilient.
The Earlier than Structure
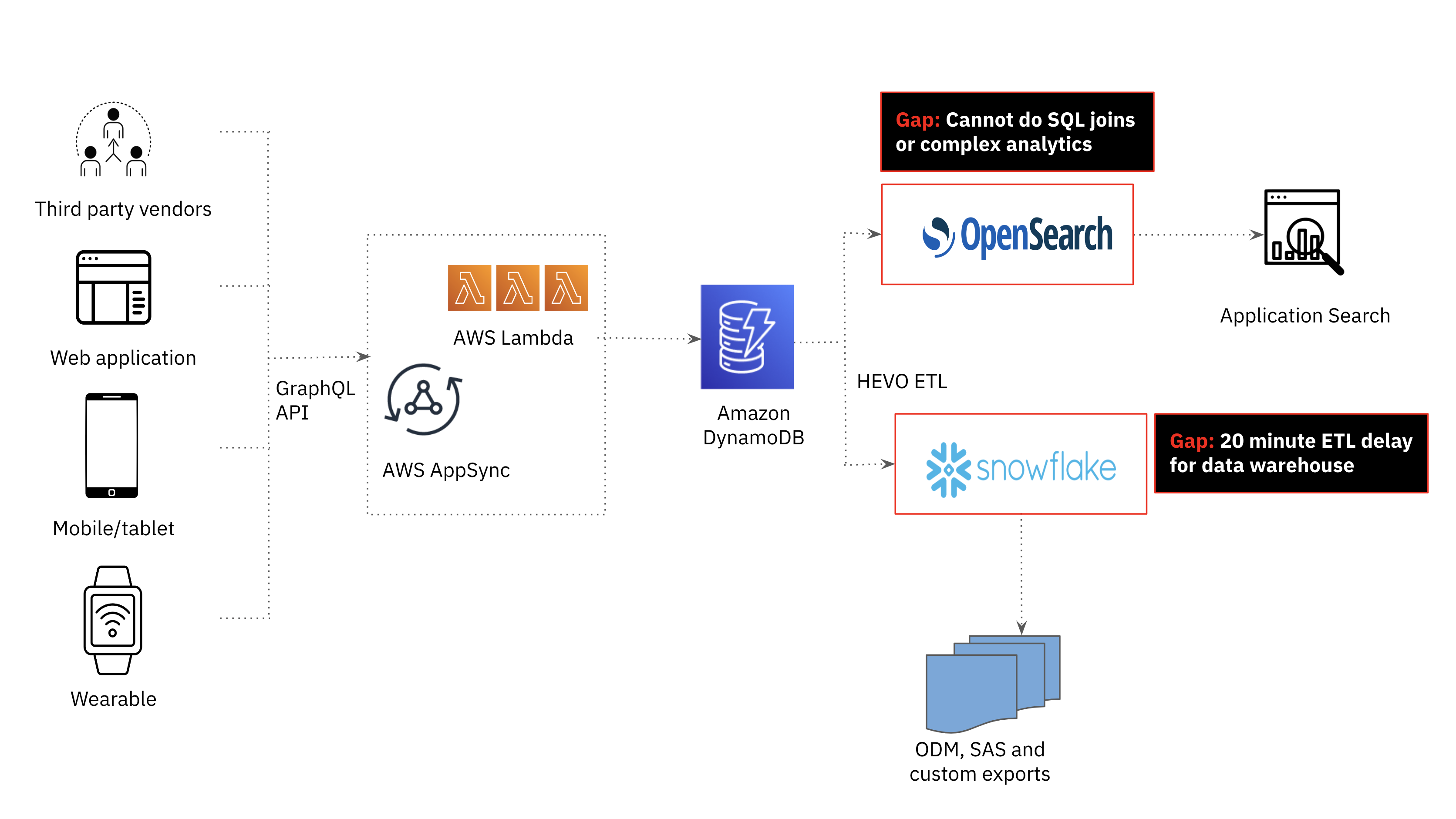
Amazon DynamoDB for Operational Workloads
Within the Scientific ink platform, third celebration vendor information, net functions, cell gadgets and wearable gadget information is saved in Amazon DynamoDB. Amazon DynamoDB�s versatile schema makes it straightforward to retailer and retrieve information in a wide range of codecs, which is especially helpful for Scientific ink�s utility that requires dealing with dynamic, semi-structured information. DynamoDB is a serverless database so the group didn’t have to fret in regards to the underlying infrastructure or scaling of the database as these are all managed by AWS.
Amazon Opensearch for Search Workloads
Whereas DynamoDB is a good alternative for quick, scalable and extremely accessible transactional workloads, it’s not the perfect for search and analytics use circumstances. Within the first technology Scientific ink platform, search and analytics was offloaded from DynamoDB to Amazon OpenSearch. As the quantity and number of information elevated, we realized the necessity for joins to assist extra superior analytics and supply real-time examine affected person monitoring. Joins usually are not a firstclass citizen in OpenSearch, requiring a lot of operationally complicated and expensive workarounds together with information denormalization, parent-child relationships, nested objects and application-side joins which are difficult to scale.
We additionally encountered information and infrastructure operational challenges when scaling OpenSearch. One information problem we confronted centered on dynamic mapping in OpenSearch or the method of routinely detecting and mapping the info kinds of fields in a doc. Dynamic mapping was helpful as we had a lot of fields with various information varieties and have been indexing information from a number of sources with completely different schemas. Nonetheless, dynamic mapping typically led to surprising outcomes, comparable to incorrect information varieties or mapping conflicts that pressured us to reindex the info.
On the infrastructure facet, despite the fact that we used managed Amazon Opensearch, we have been nonetheless accountable for cluster operations together with managing nodes, shards and indexes. We discovered that as the dimensions of the paperwork elevated we wanted to scale up the cluster which is a guide, time-consuming course of. Moreover, as OpenSearch has a tightly coupled structure with compute and storage scaling collectively, we needed to overprovision compute assets to assist the rising variety of paperwork. This led to compute wastage and better prices and decreased effectivity. Even when we may have made complicated analytics work on OpenSearch, we’d have evaluated further databases as the info engineering and operational administration was important.
Snowflake for Information Warehousing Workloads
We additionally investigated the potential of our cloud information warehouse, Snowflake, to be the serving layer for analytics in our utility. Snowflake was used to supply weekly consolidated experiences to scientific trial sponsors and supported SQL analytics, assembly the complicated analytics necessities of the appliance. That mentioned, offloading DynamoDB information to Snowflake was too delayed; at a minimal, we may obtain a 20 minute information latency which fell exterior the time window required for this use case.
Necessities
Given the gaps within the present structure, we got here up with the next necessities for the substitute of OpenSearch because the serving layer:
- Actual-time streaming ingest: Information adjustments from DynamoDB must be seen and queryable within the downstream database inside seconds
- Millisecond-latency complicated analytics (together with joins): The database should be capable to consolidate international trial information on sufferers right into a 360-degree view. This consists of supporting complicated sorting and filtering of the info and aggregations of hundreds of various entities.
- Extremely Resilient: The database is designed to keep up availability and reduce information loss within the face of varied kinds of failures and disruptions.
- Scalable: The database is cloud-native and might scale on the click on of a button or an API name with no downtime. We had invested in a serverless structure with Amazon DynamoDB and didn’t need the engineering group to handle cluster-level operations transferring ahead.
The After Structure
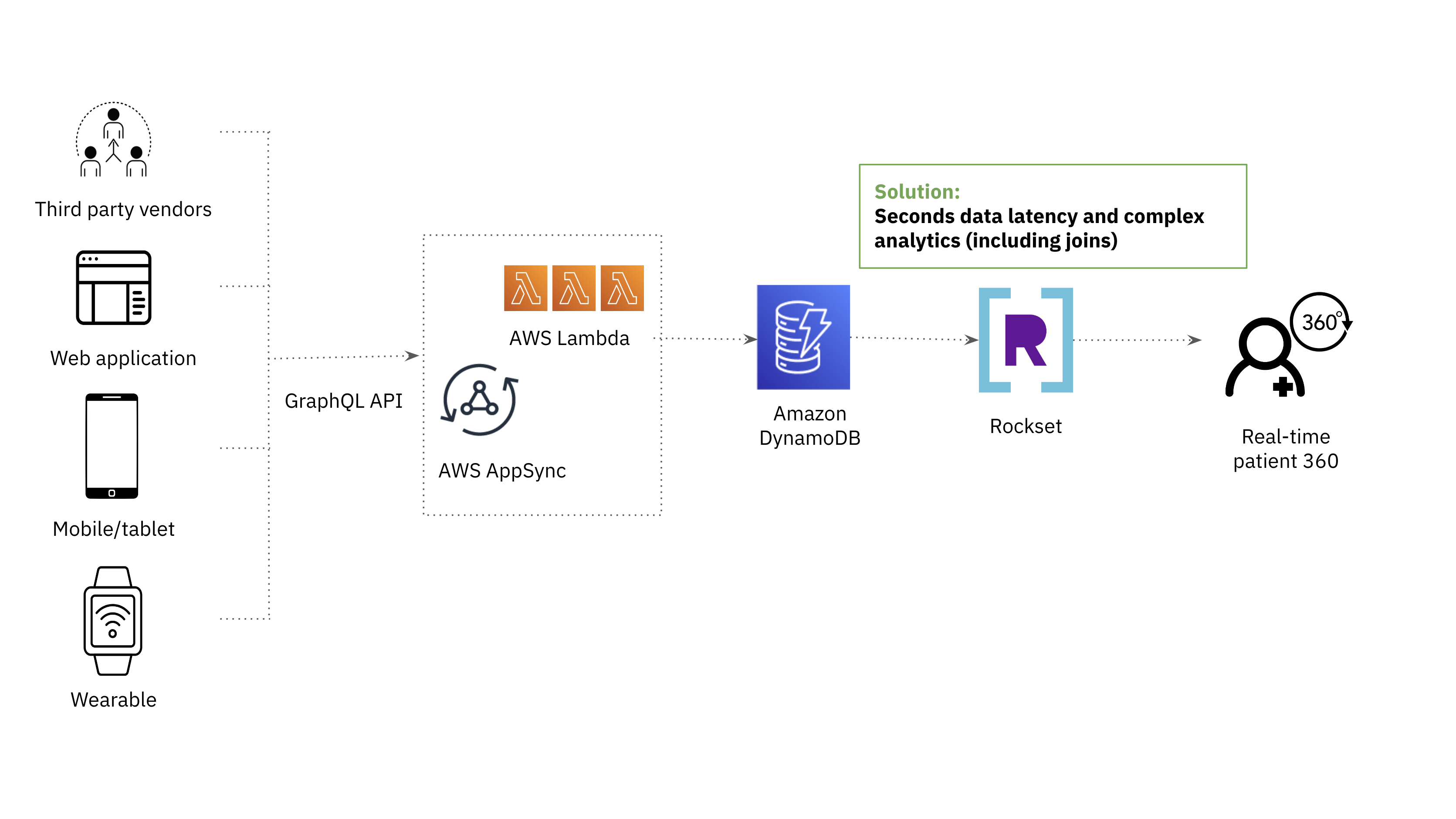
Rockset initially got here on our radar as a substitute for OpenSearch for its assist of complicated analytics on low latency information.
Each OpenSearch and Rockset use indexing to allow quick querying over giant quantities of knowledge. The distinction is that Rockset employs a Converged Index which is a mixture of a search index, columnar retailer and row retailer for optimum question efficiency. The Converged Index helps a SQL-based question language, which allows us to fulfill the requirement for complicated analytics.
Along with Converged Indexing, there have been different options that piqued our curiosity and made it straightforward to start out efficiency testing Rockset on our personal information and queries.
- Constructed-in connector to DynamoDB: New information from our DynamoDB tables are mirrored and made queryable in Rockset with only some seconds delay. This made it straightforward for Rockset to suit into our present information stack.
- Means to take a number of information varieties into the identical subject: This addressed the info engineering challenges that we confronted with dynamic mapping in OpenSearch, guaranteeing that there have been no breakdowns in our ETL course of and that queries continued to ship responses even when there have been schema adjustments.
- Cloud-native structure: We’ve additionally invested in a serverless information stack for resource-efficiency and decreased operational overhead. We have been in a position to scale ingest compute, question compute and storage independently with Rockset in order that we not must overprovision assets.
Efficiency Outcomes
As soon as we decided that Rockset fulfilled the wants of our utility, we proceeded to evaluate the database’s ingestion and question efficiency. We ran the next checks on Rockset by constructing a Lambda operate with Node.js:
Ingest Efficiency
The frequent sample we see is quite a lot of small writes, ranging in measurement from 400 bytes to 2 kilobytes, grouped collectively and being written to the database continuously. We evaluated ingest efficiency by producing X writes into DynamoDB in fast succession and recording the common time in milliseconds that it took for Rockset to sync that information and make it queryable, also referred to as information latency.
To run this efficiency check, we used a Rockset medium digital occasion with 8 vCPU of compute and 64 GiB of reminiscence.
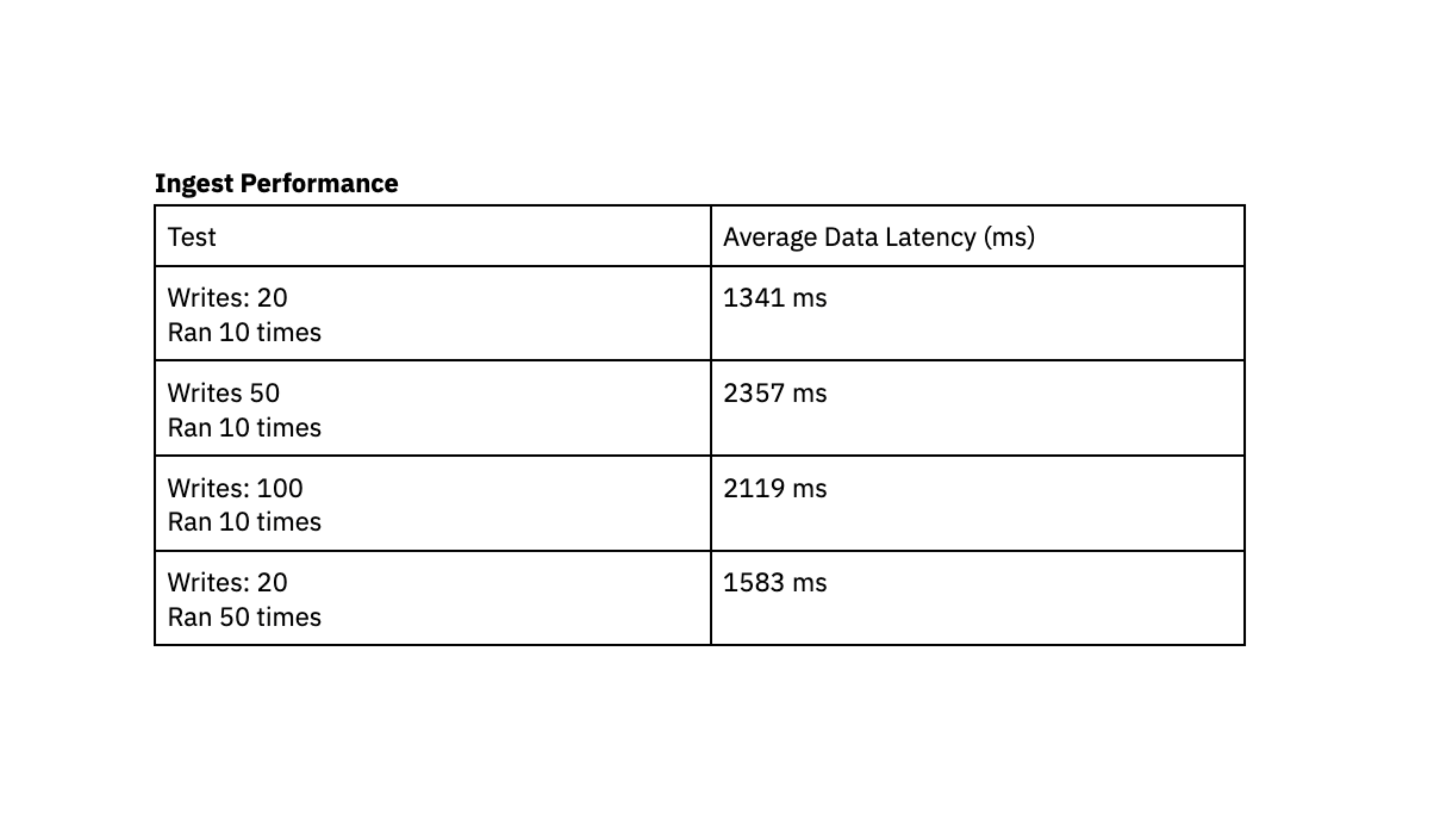
The efficiency checks point out that Rockset is able to attaining a information latency beneath 2.4 seconds, which represents the length between the technology of knowledge in DynamoDB and its availability for querying in Rockset. This load testing made us assured that we may persistently entry information roughly 2 seconds after writing to DynamoDB, giving customers up-to-date information of their dashboards. Up to now, we struggled to attain predictable latency with Elasticsearch and have been excited by the consistency that we noticed with Rockset throughout load testing.
Question Efficiency
For question efficiency, we executed X queries randomly each 10-60 milliseconds. We ran two checks utilizing queries with completely different ranges of complexity:
- Question 1: Easy question on just a few fields of knowledge. Dataset measurement of ~700K information and a couple of.5 GB.
- Question 2: Complicated question that expands arrays into a number of rows utilizing an unnest operate. Information is filtered on the unnested fields. Two datasets have been joined collectively: one dataset had 700K rows and a couple of.5 GB, the opposite dataset had 650K rows and 3GB.
We once more ran the checks on a Rockset medium digital occasion with 8 vCPU of compute and 64 GiB of reminiscence.
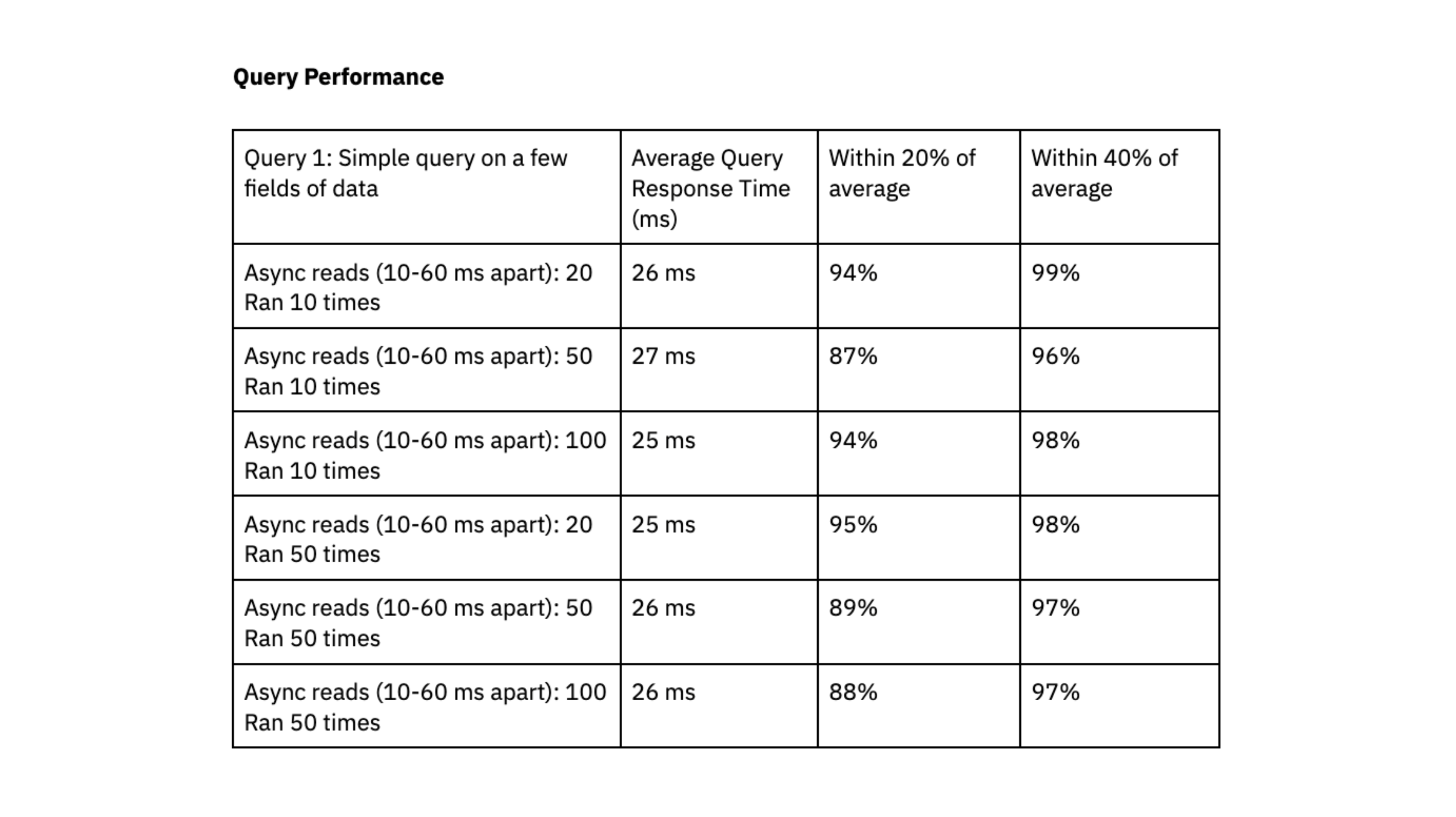
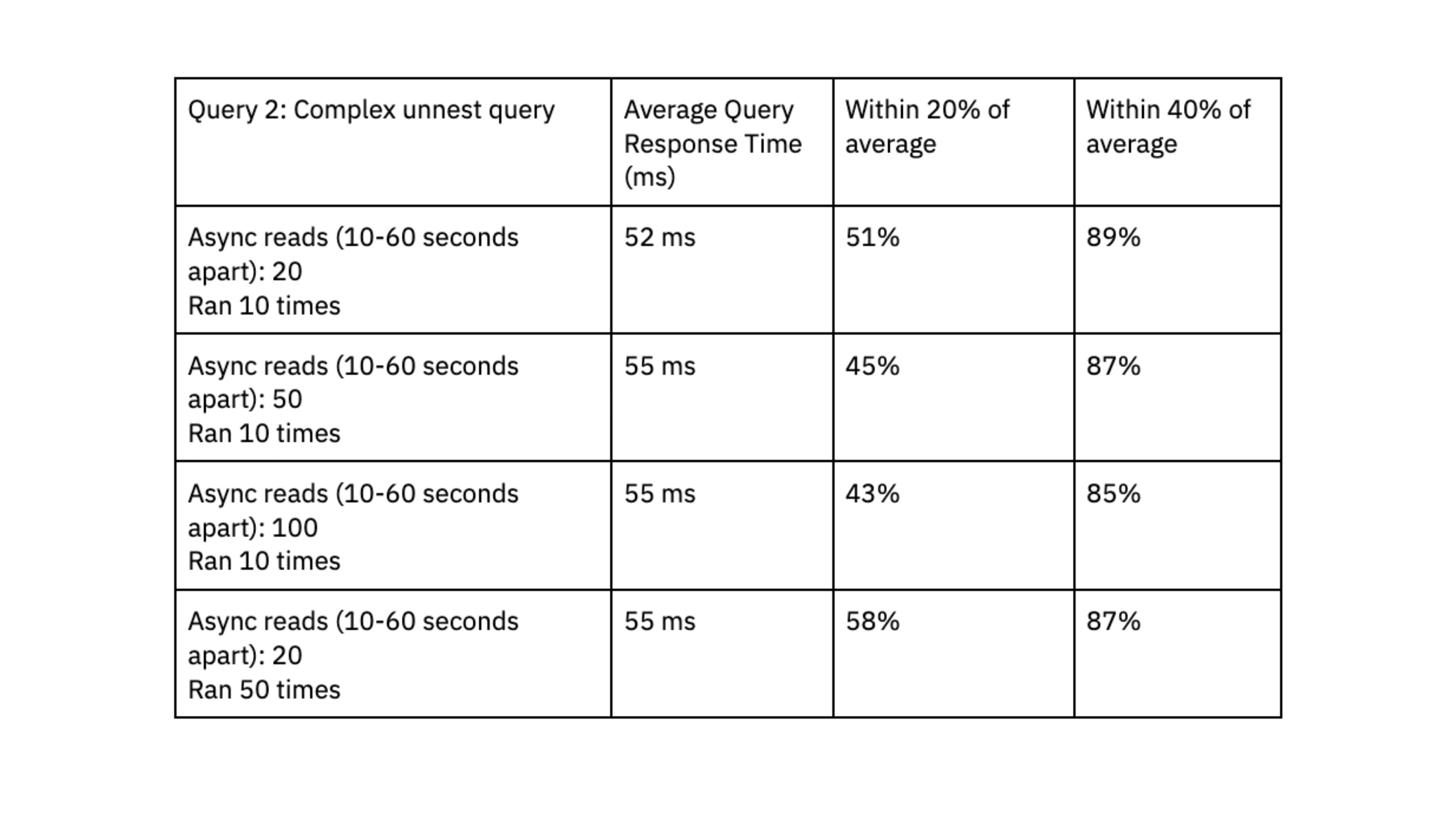
Rockset was in a position to ship question response instances within the vary of double-digit milliseconds, even when dealing with workloads with excessive ranges of concurrency.
To find out if Rockset can scale linearly, we evaluated question efficiency on a small digital occasion, which had 4vCPU of compute and 32 GiB of reminiscence, towards the medium digital occasion. The outcomes confirmed that the medium digital occasion decreased question latency by an element of 1.6x for the primary question and 4.5x for the second question, suggesting that Rockset can scale effectively for our workload.
We appreciated that Rockset achieved predictable question efficiency, clustered inside 40% and 20% of the common, and that queries persistently delivered in double-digit milliseconds; this quick question response time is important to our consumer expertise.
Conclusion
We�re at the moment phasing real-time scientific trial monitoring into manufacturing as the brand new operational information hub for scientific groups. We’ve been blown away by the velocity of Rockset and its skill to assist complicated filters, joins, and aggregations. Rockset achieves double-digit millisecond latency queries and might scale ingest to assist real-time updates, inserts and deletes from DynamoDB.
Not like OpenSearch, which required guide interventions to attain optimum efficiency, Rockset has confirmed to require minimal operational effort on our half. Scaling up our operations to accommodate bigger digital cases and extra scientific sponsors occurs with only a easy push of a button.
Over the subsequent 12 months, we�re excited to roll out the real-time examine participant monitoring to all clients and proceed our management within the digital transformation of scientific trials.