
{kind=link}
Our dialogue to date has been anchored across the household of linear fashions. Every strategy, from easy linear regression to penalized methods like Lasso and Ridge, has supplied invaluable insights into predicting steady outcomes primarily based on linear relationships. As we start our exploration of tree-based fashions, it’s essential to reiterate that our focus stays on regression. Whereas tree-based fashions are versatile, how they deal with, consider, and optimize outcomes differs considerably between classification and regression duties.
Tree-based regression fashions are highly effective instruments in machine studying that may deal with non-linear relationships and complicated knowledge constructions. On this publish, we’ll introduce a spectrum of tree-based fashions, highlighting their strengths and weaknesses. Then, we’ll dive right into a sensible instance of implementing and visualizing a Choice Tree utilizing sklearn and matplotlib. Lastly, we’ll improve our visualization utilizing dtreeviz, a software that gives extra detailed insights.
Let’s get began.

Branching Out: Exploring Tree-Based mostly Fashions for Regression
Photograph by Michael Held. Some rights reserved.
Overview
This publish is split into three elements; they’re:
- A Spectrum of Tree-Based mostly Regression Fashions
- Visualization of a Choice Tree with
sklearnandmatplotlib - An Enhanced Visualization with
dtreeviz
A Spectrum of Tree-Based mostly Regression Fashions
Tree-based fashions are available in varied complexities, every with distinctive capabilities and fitted to completely different situations. To higher perceive the vary of tree-based regression fashions, let’s check out the next visible that summarizes just a few in style ones:
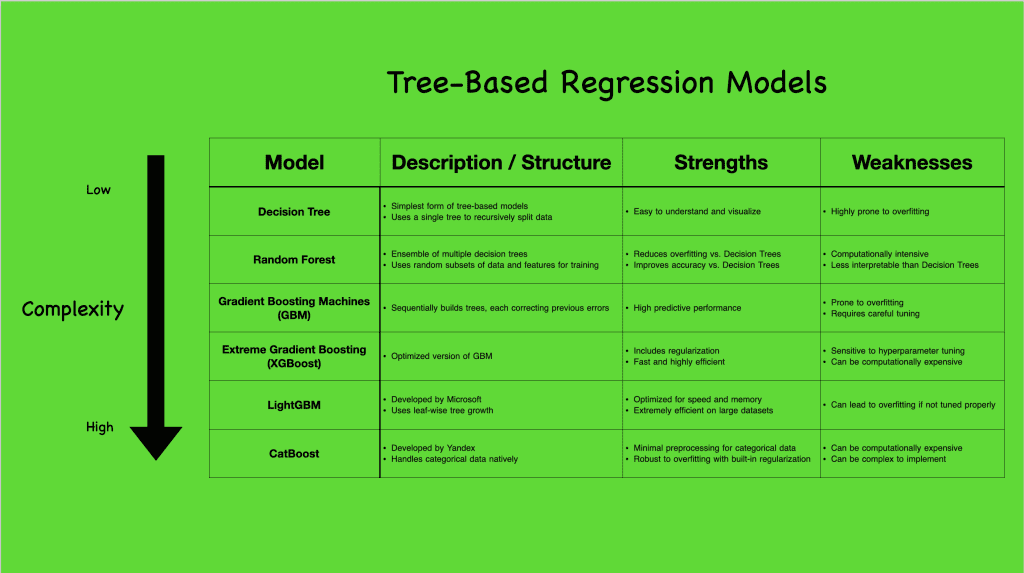
Tree-based regression fashions. Click on to enlarge.
Beginning with the Choice Tree (CART), the only kind, we see a mannequin that constructs a single tree to seize knowledge splits. Although simple, it’s susceptible to overfitting however units the stage for extra complicated fashions. Progressing to ensemble strategies like Random Forest and Gradient Boosting Machines (GBM), and even additional to superior algorithms like XGBoost, LightGBM, and CatBoost, we observe more and more subtle methods to deal with knowledge, scale back overfitting, and enhance predictive accuracy.
Whereas linear fashions assume a direct, linear relationship between options and outcomes, tree-based fashions break the mildew by effortlessly capturing non-linear interactions. This non-linearity permits tree-based fashions to uncover intricate patterns within the knowledge, making them significantly highly effective in real-world purposes the place relationships between variables are seldom purely linear. They’re strong to outliers and versatile with completely different knowledge sorts, making no stringent calls for on characteristic scaling. Nevertheless, this flexibility comes with challenges, notably overfitting and computational calls for, particularly because the fashions develop in complexity.
Visualization of a Choice Tree with sklearn and matplotlib
Within the earlier part, we explored a spectrum of tree-based regression fashions and their various complexities. Now, let’s dive deeper into one of many easiest but elementary fashions: the Choice Tree. We’ll use the Ames housing dataset to grasp how a Choice Tree works in observe. The next code block demonstrates easy methods to import the required libraries, extract numerical knowledge with out lacking values (for simplicity), prepare a Choice Tree mannequin, and visualize the ensuing tree construction utilizing Matplotlib and the in-built sklearn.tree.plot_tree operate:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
# Import the required libraries import pandas as pd from sklearn import tree import matplotlib.pyplot as plt from sklearn.tree import DecisionTreeRegressor from sklearn.model_selection import train_test_break up
# Load all of the numeric options with none lacking values Ames = pd.read_csv(‘Ames.csv’).select_dtypes(embody=[‘int64’, ‘float64’]) Ames.dropna(axis=1, inplace=True) X = Ames.drop(‘SalePrice’, axis=1) y = Ames[‘SalePrice’]
# Break up the info X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Initialize and match the Choice Tree tree_model = DecisionTreeRegressor(max_depth=3) tree_model.match(X_train, y_train)
# Visualize the choice tree with sklearn plt.determine(figsize=(20, 10)) tree.plot_tree(tree_model, feature_names=X.columns, crammed=True, impurity=False, rounded=True, precision=2, fontsize=12)
plt.present() |
We intentionally set max_depth=3 to constrain the complexity of the tree. This parameter limits the utmost depth of the tree, making certain that it doesn’t develop too deep. By doing this, we make the tree less complicated and simpler to visualise, which helps in understanding the essential construction and decision-making means of the mannequin with out getting misplaced in too many particulars.
Right here’s the ensuing visualization of our Choice Tree:
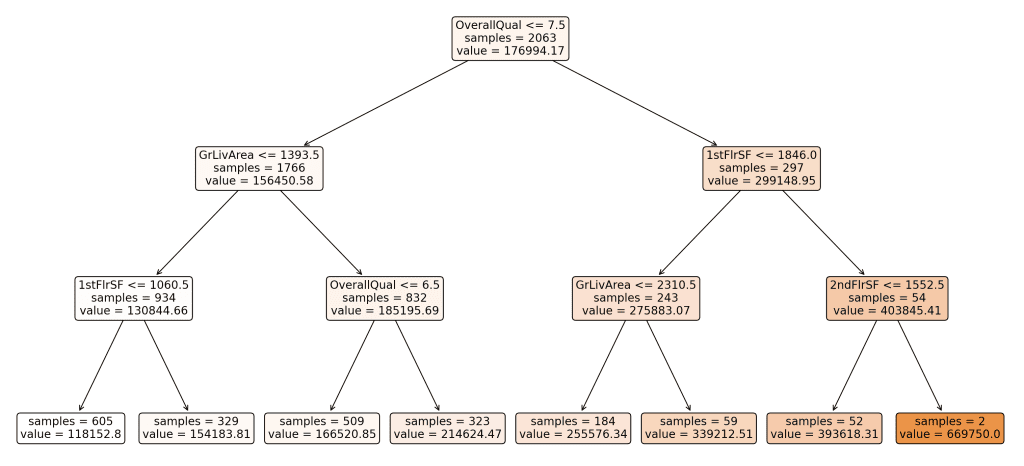
Derived resolution tree. Click on to enlarge.
This tree represents how the mannequin splits the info primarily based on varied options to foretell the sale value of homes. Every node within the tree represents a call level primarily based on the worth of a characteristic, and the leaves characterize the ultimate predicted values.
Understanding the Splits:
- Why did the tree break up the best way it did?
The Choice Tree algorithm splits the info at every node to attenuate the Imply Squared Error (MSE) of the goal variable, which on this case is the sale value. MSE measures the typical of the squares of the errors—that’s, the distinction between the anticipated and precise values. By selecting splits that scale back MSE, the tree goals to create teams of knowledge which might be as homogeneous as doable when it comes to the goal variable. - What options had been chosen for the break up?
The options chosen for the splits on this tree embody “OverallQual”, “GrLivArea”, “1stFlrSF”, and “2ndFlrSF’. These options had been chosen primarily based on their means to cut back the MSE when used to separate the info. The degrees or thresholds for these splits (e.g., OverallQual <= 7.5) had been decided in the course of the coaching course of to optimize the separation of knowledge factors into extra homogeneous teams. - Deciphering the Splits and Arrows:
- Every node within the tree features a characteristic and a threshold worth. For instance, the basis node splits the info primarily based on whether or not “OverallQual” is lower than or equal to 7.5.
- Arrows pointing left characterize knowledge factors that meet the situation (e.g., OverallQual <= 7.5), whereas arrows pointing proper characterize knowledge factors that don’t meet the situation (e.g., OverallQual > 7.5).
- Subsequent splits additional divide the info to refine the predictions, with every break up aiming to cut back the MSE inside the ensuing teams.
- Coloration Coding of Branches:
The branches within the visualization are color-coded from white to darker shades to point the anticipated worth at every node. Lighter colours characterize decrease predicted values, whereas darker shades point out greater predicted values. This shade gradient helps to visually differentiate the predictions throughout the tree and perceive the distribution of sale costs. - Leaves and Closing Predictions:
The leaves of the tree characterize the ultimate predicted values for the goal variable. Every leaf node reveals the anticipated sale value (e.g., worth = 118152.80) and the variety of samples that fall into that leaf (e.g., samples = 605). These values are calculated as the typical sale value of all knowledge factors inside that group.
The Choice Tree mannequin is simple and interpretable, making it a superb start line for understanding extra complicated tree-based fashions. Nevertheless, as talked about earlier, one main disadvantage is its tendency to overfit, particularly with deeper bushes. Overfitting happens when the mannequin captures noise within the coaching knowledge, resulting in poor generalization on unseen knowledge.
An Enhanced Visualization with dtreeviz
Within the earlier half, we visualized a Choice Tree utilizing matplotlib and the built-in sklearn.tree.plot_tree operate to grasp the decision-making means of the mannequin. Whereas this offers an excellent overview, extra subtle instruments can be found that supply enhanced visualizations.
On this part, we are going to use dtreeviz, a library that gives detailed visualizations for Choice Bushes. For an inventory of dependencies and libraries which will have to be put in relying in your working system, please confer with this GitHub repository. The next code block demonstrates easy methods to import the required libraries, put together the info, prepare a Choice Tree mannequin, and visualize the tree utilizing dtreeviz.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
# Import the required libraries import pandas as pd from sklearn.tree import DecisionTreeRegressor from sklearn.model_selection import train_test_split import dtreeviz
# Load all of the numeric options with none lacking values Ames = pd.read_csv(‘Ames.csv’).select_dtypes(embody=[‘int64’, ‘float64’]) Ames.dropna(axis=1, inplace=True) X = Ames.drop(‘SalePrice’, axis=1) y = Ames[‘SalePrice’]
# Break up the info X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Initialize and match the Choice Tree tree_model = DecisionTreeRegressor(max_depth=3) tree_model.match(X_train.values, y_train)
# Visualize the choice tree utilizing dtreeviz viz = dtreeviz.mannequin(tree_model, X_train, y_train, target_name=‘SalePrice’, feature_names=X_train.columns.tolist())
# In Jupyter Pocket book, you may straight view the visible utilizing the under: # viz.view() # Renders and shows the SVG visualization
# In PyCharm, you may render and show the SVG picture: v = viz.view() # render as SVG into inside object v.present() # pop up window |
Right here’s the improved visualization (as soon as once more with max_depth=3) utilizing dtreeviz:
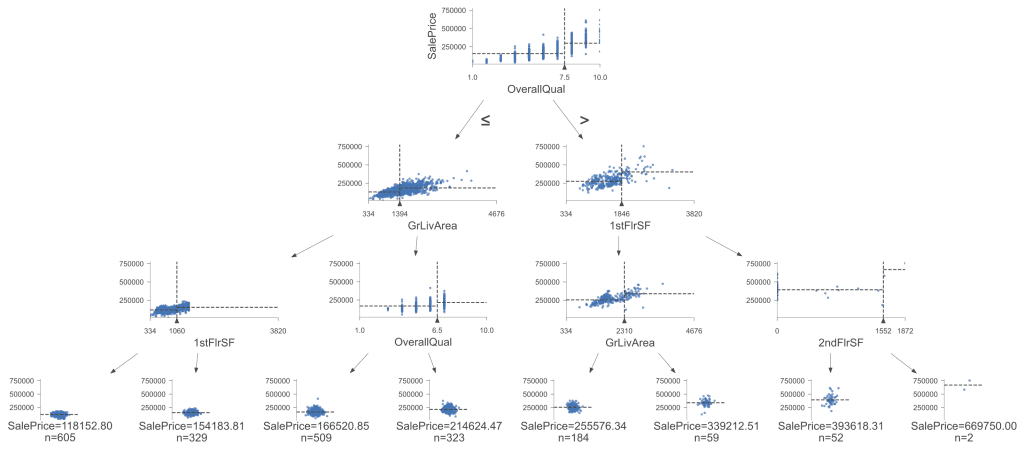
Visualization of the choice tree. Click on to enlarge.
This visualization offers extra info and an in depth view of the Choice Tree. The scatter plots at every node assist us perceive every break up’s characteristic distributions and influence, making it significantly helpful for understanding complicated splits and the significance of various options. The tree splits on the identical guidelines and resolution boundaries as our first visible, resulting in the identical conclusions. Nevertheless, dtreeviz makes it simpler to visualise homogeneous or clustered knowledge because the bushes get deeper, offering a clearer image of how knowledge factors group collectively primarily based on the splits.
Additional Studying
APIs
GitHub / PIP
Tutorials
Sources
Abstract
On this publish, we launched tree-based regression fashions, specializing in Choice Bushes. We began with an summary of assorted tree-based fashions, highlighting their strengths and weaknesses. We then visualized a Choice Tree utilizing sklearn and matplotlib to grasp its primary construction and decision-making course of. Lastly, we enhanced the visualization utilizing dtreeviz, offering deeper insights and a extra interactive mannequin view.
Particularly, you discovered:
- The strengths and weaknesses of assorted tree-based regression fashions.
- Easy methods to prepare and visualize a Choice Tree utilizing
sklearnandmatplotlib. - Easy methods to use
dtreevizfor extra detailed Choice Tree visualizations.
Do you’ve gotten any questions? Please ask your questions within the feedback under, and I’ll do my greatest to reply.
Get Began on The Newbie’s Information to Information Science!

Study the mindset to turn into profitable in knowledge science tasks
…utilizing solely minimal math and statistics, purchase your talent by means of quick examples in Python
Uncover how in my new E book:
The Newbie’s Information to Information Science
It offers self-study tutorials with all working code in Python to show you from a novice to an skilled. It reveals you easy methods to discover outliers, affirm the normality of knowledge, discover correlated options, deal with skewness, test hypotheses, and far more…all to assist you in making a narrative from a dataset.