
{kind=link}
Categorical variables are pivotal as they usually carry important data that influences the end result of predictive fashions. Nonetheless, their non-numeric nature presents distinctive challenges in mannequin processing, necessitating particular methods for encoding. This publish will start by discussing the several types of categorical information usually encountered in datasets. We are going to discover ordinal encoding in-depth and the way it may be leveraged when implementing a Determination Tree Regressor. By way of sensible Python examples utilizing the OrdinalEncoder from sklearn and the Ames Housing dataset, this information will offer you the talents to implement these methods successfully. Moreover, we’ll visually show how these encoded variables affect the selections of a Determination Tree Regressor.
Let’s get began.

Determination Timber and Ordinal Encoding
Picture by Kai Pilger. Some rights reserved.
Overview
This publish is split into three components; they’re:
- Understanding Categorical Variables: Ordinal vs. Nominal
- Implementing Ordinal Encoding in Python
- Visualizing Determination Timber: Insights from Ordinally Encoded Knowledge
Understanding Categorical Variables: Ordinal vs. Nominal
Categorical options in datasets are elementary components that want cautious dealing with throughout preprocessing to make sure correct mannequin predictions. These options can broadly be labeled into two varieties: ordinal and nominal. Ordinal options possess a pure order or hierarchy amongst their classes. An instance is the characteristic “ExterQual” within the Ames dataset, which describes the standard of the fabric on the outside of a home with ranges like “Poor”, “Truthful”, “Common”, “Good”, and “Glorious”. The order amongst these classes is important and could be utilized in predictive modeling. Nominal options, in distinction, don’t suggest any inherent order. Classes are distinct and don’t have any order relationship between them. For example, the “Neighborhood” characteristic represents varied names of neighborhoods like “CollgCr”, “Veenker”, “Crawfor”, and many others., with none intrinsic rating or hierarchy.
The preprocessing of categorical variables is essential as a result of most machine studying algorithms require enter information in numerical format. This conversion from categorical to numerical is usually achieved via encoding. The selection of encoding technique is pivotal and is influenced by each the kind of categorical variable and the mannequin getting used.
Encoding Methods for Machine Studying Fashions
Linear fashions, corresponding to linear regression, sometimes make use of one-hot encoding for each ordinal and nominal options. This technique transforms every class into a brand new binary variable, guaranteeing that the mannequin treats every class as an impartial entity with none ordinal relationship. That is important as a result of linear fashions assume interval information. That’s, linear fashions interpret numerical enter linearly, that means the numerical worth assigned to every class in ordinal encoding might mislead the mannequin. Every incremental integer worth in ordinal encoding could be incorrectly assumed by a linear mannequin to mirror an equal step enhance within the underlying quantitative measure, which may distort the mannequin output if this assumption doesn’t maintain.
Tree-based fashions, which embody algorithms like determination timber and random forests, deal with categorical information otherwise. These fashions can profit from ordinal encoding for ordinal options as a result of they make binary splits based mostly on the characteristic values. The inherent order preserved in ordinal encoding can help these fashions in making simpler splits. Tree-based fashions don’t inherently consider the arithmetic distinction between classes. As an alternative, they assess whether or not a selected cut up at any given encoded worth finest segments the goal variable into its lessons or ranges. In contrast to linear fashions, this makes them much less delicate to how the classes are spaced.
Now that we’ve explored the kinds of categorical variables and their implications for machine studying fashions, the following half will information you thru the sensible software of those ideas. We’ll dive into learn how to implement ordinal encoding in Python utilizing the Ames dataset, offering you with the instruments to effectively put together your information for mannequin coaching.
Implementing Ordinal Encoding in Python
To implement ordinal encoding in Python, we use the OrdinalEncoder from sklearn.preprocessing. This software is especially helpful for making ready ordinal options for tree-based fashions. It permits us to specify the order of classes manually, guaranteeing that the encoding respects the pure hierarchy of the info. We will obtain this utilizing the knowledge within the expanded information dictionary:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 |
# Import vital libraries import pandas as pd from sklearn.pipeline import Pipeline from sklearn.impute import SimpleImputer from sklearn.compose import ColumnTransformer from sklearn.preprocessing import FunctionTransformer, OrdinalEncoder
# Load the dataset Ames = pd.read_csv(‘Ames.csv’)
# Manually specify the classes for ordinal encoding in accordance with the info dictionary ordinal_order = { ‘Electrical’: [‘Mix’, ‘FuseP’, ‘FuseF’, ‘FuseA’, ‘SBrkr’], # Electrical system ‘LotShape’: [‘IR3’, ‘IR2’, ‘IR1’, ‘Reg’], # Basic form of property ‘Utilities’: [‘ELO’, ‘NoSeWa’, ‘NoSewr’, ‘AllPub’], # Kind of utilities out there ‘LandSlope’: [‘Sev’, ‘Mod’, ‘Gtl’], # Slope of property ‘ExterQual’: [‘Po’, ‘Fa’, ‘TA’, ‘Gd’, ‘Ex’], # Evaluates the standard of the fabric on the outside ‘ExterCond’: [‘Po’, ‘Fa’, ‘TA’, ‘Gd’, ‘Ex’], # Evaluates the current situation of the fabric on the outside ‘BsmtQual’: [‘None’, ‘Po’, ‘Fa’, ‘TA’, ‘Gd’, ‘Ex’], # Top of the basement ‘BsmtCond’: [‘None’, ‘Po’, ‘Fa’, ‘TA’, ‘Gd’, ‘Ex’], # Basic situation of the basement ‘BsmtExposure’: [‘None’, ‘No’, ‘Mn’, ‘Av’, ‘Gd’], # Walkout or backyard stage basement partitions ‘BsmtFinType1’: [‘None’, ‘Unf’, ‘LwQ’, ‘Rec’, ‘BLQ’, ‘ALQ’, ‘GLQ’], # High quality of basement completed space ‘BsmtFinType2’: [‘None’, ‘Unf’, ‘LwQ’, ‘Rec’, ‘BLQ’, ‘ALQ’, ‘GLQ’], # High quality of second basement completed space ‘HeatingQC’: [‘Po’, ‘Fa’, ‘TA’, ‘Gd’, ‘Ex’], # Heating high quality and situation ‘KitchenQual’: [‘Po’, ‘Fa’, ‘TA’, ‘Gd’, ‘Ex’], # Kitchen high quality ‘Practical’: [‘Sal’, ‘Sev’, ‘Maj2’, ‘Maj1’, ‘Mod’, ‘Min2’, ‘Min1’, ‘Typ’], # House performance ‘FireplaceQu’: [‘None’, ‘Po’, ‘Fa’, ‘TA’, ‘Gd’, ‘Ex’], # Fire high quality ‘GarageFinish’: [‘None’, ‘Unf’, ‘RFn’, ‘Fin’], # Inside end of the storage ‘GarageQual’: [‘None’, ‘Po’, ‘Fa’, ‘TA’, ‘Gd’, ‘Ex’], # Storage high quality ‘GarageCond’: [‘None’, ‘Po’, ‘Fa’, ‘TA’, ‘Gd’, ‘Ex’], # Storage situation ‘PavedDrive’: [‘N’, ‘P’, ‘Y’], # Paved driveway ‘PoolQC’: [‘None’, ‘Fa’, ‘TA’, ‘Gd’, ‘Ex’], # Pool high quality ‘Fence’: [‘None’, ‘MnWw’, ‘GdWo’, ‘MnPrv’, ‘GdPrv’] # Fence high quality }
# Extract listing of ALL ordinal options from dictionary ordinal_features = listing(ordinal_order.keys())
# Listing of ordinal options besides Electrical ordinal_except_electrical = [feature for feature in ordinal_features if feature != ‘Electrical’]
# Particular transformer for ‘Electrical’ utilizing the mode for imputation electrical_imputer = Pipeline(steps=[ (‘impute_electrical’, SimpleImputer(strategy=‘most_frequent’)) ])
# Helper operate to fill ‘None’ for different ordinal options def fill_none(X): return X.fillna(“None”)
# Pipeline for ordinal options: Fill lacking values with ‘None’ ordinal_imputer = Pipeline(steps=[ (‘fill_none’, FunctionTransformer(fill_none, validate=False)) ])
# Preprocessor for filling lacking values preprocessor_fill = ColumnTransformer(transformers=[ (‘electrical’, electrical_imputer, [‘Electrical’]), (‘cat’, ordinal_imputer, ordinal_except_electrical) ])
# Apply preprocessor for filling lacking values Ames_ordinal = preprocessor_fill.fit_transform(Ames[ordinal_features])
# Convert again to DataFrame to use OrdinalEncoder Ames_ordinal = pd.DataFrame(Ames_ordinal, columns=[‘Electrical’] + ordinal_except_electrical)
# Apply Ordinal Encoding classes = [ordinal_order[feature] for characteristic in ordinal_features] ordinal_encoder = OrdinalEncoder(classes=classes) Ames_ordinal_encoded = ordinal_encoder.fit_transform(Ames_ordinal) Ames_ordinal_encoded = pd.DataFrame(Ames_ordinal_encoded, columns=[‘Electrical’] + ordinal_except_electrical) |
The code block above effectively handles the preprocessing of categorical variables by first filling lacking values after which making use of the suitable encoding technique. By viewing the dataset earlier than encoding, we are able to affirm that our preprocessing steps have been appropriately utilized:
|
# Ames dataset of ordinal options previous to ordinal encoding print(Ames_ordinal) |
|
Electrical LotShape Utilities LandSlope … GarageCond PavedDrive PoolQC Fence 0 SBrkr Reg AllPub Gtl … TA Y None None 1 SBrkr Reg AllPub Gtl … TA Y None None 2 SBrkr Reg AllPub Gtl … Po N None None 3 SBrkr Reg AllPub Gtl … TA N None None 4 SBrkr Reg AllPub Gtl … TA Y None None … … … … … … … … … … 2574 FuseF Reg AllPub Gtl … Po P None None 2575 FuseA IR1 AllPub Gtl … TA Y None None 2576 FuseA Reg AllPub Gtl … TA Y None None 2577 SBrkr Reg AllPub Gtl … TA Y None None 2578 SBrkr IR1 AllPub Gtl … TA Y None None
[2579 rows x 21 columns] |
The output above highlights the ordinal options within the Ames dataset previous to any ordinal encoding. Under, we illustrate the particular data we offer to the OrdinalEncoder. Please word that we don’t present a listing of options. We merely present the rating of every characteristic within the order they seem in our dataset.
|
# The knowledge we enter into ordinal encoder, it is going to robotically assign 0, 1, 2, 3, and many others. print(classes) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
[[‘Mix’, ‘FuseP’, ‘FuseF’, ‘FuseA’, ‘SBrkr’], [‘IR3’, ‘IR2’, ‘IR1’, ‘Reg’], [‘ELO’, ‘NoSeWa’, ‘NoSewr’, ‘AllPub’], [‘Sev’, ‘Mod’, ‘Gtl’], [‘Po’, ‘Fa’, ‘TA’, ‘Gd’, ‘Ex’], [‘Po’, ‘Fa’, ‘TA’, ‘Gd’, ‘Ex’], [‘None’, ‘Po’, ‘Fa’, ‘TA’, ‘Gd’, ‘Ex’], [‘None’, ‘Po’, ‘Fa’, ‘TA’, ‘Gd’, ‘Ex’], [‘None’, ‘No’, ‘Mn’, ‘Av’, ‘Gd’], [‘None’, ‘Unf’, ‘LwQ’, ‘Rec’, ‘BLQ’, ‘ALQ’, ‘GLQ’], [‘None’, ‘Unf’, ‘LwQ’, ‘Rec’, ‘BLQ’, ‘ALQ’, ‘GLQ’], [‘Po’, ‘Fa’, ‘TA’, ‘Gd’, ‘Ex’], [‘Po’, ‘Fa’, ‘TA’, ‘Gd’, ‘Ex’], [‘Sal’, ‘Sev’, ‘Maj2’, ‘Maj1’, ‘Mod’, ‘Min2’, ‘Min1’, ‘Typ’], [‘None’, ‘Po’, ‘Fa’, ‘TA’, ‘Gd’, ‘Ex’], [‘None’, ‘Unf’, ‘RFn’, ‘Fin’], [‘None’, ‘Po’, ‘Fa’, ‘TA’, ‘Gd’, ‘Ex’], [‘None’, ‘Po’, ‘Fa’, ‘TA’, ‘Gd’, ‘Ex’], [‘N’, ‘P’, ‘Y’], [‘None’, ‘Fa’, ‘TA’, ‘Gd’, ‘Ex’], [‘None’, ‘MnWw’, ‘GdWo’, ‘MnPrv’, ‘GdPrv’]] |
This units the stage for an efficient software of ordinal encoding, the place the pure ordering of classes is essential for subsequent mannequin coaching. Every class inside a characteristic can be transformed to a numerical worth that displays its rank or significance as specified, with out assuming any equidistant spacing between them.
|
# Ames dataset of ordinal options after ordinal encoding print(Ames_ordinal_encoded) |
The remodeled dataset is proven beneath. It’s extremely really useful to do a fast test in opposition to the unique dataset to make sure that the outcomes align with the knowledge we obtained from the info dictionary.
|
Electrical LotShape Utilities … PavedDrive PoolQC Fence 0 4.0 3.0 3.0 … 2.0 0.0 0.0 1 4.0 3.0 3.0 … 2.0 0.0 0.0 2 4.0 3.0 3.0 … 0.0 0.0 0.0 3 4.0 3.0 3.0 … 0.0 0.0 0.0 4 4.0 3.0 3.0 … 2.0 0.0 0.0 … … … … … … … … 2574 2.0 3.0 3.0 … 1.0 0.0 0.0 2575 3.0 2.0 3.0 … 2.0 0.0 0.0 2576 3.0 3.0 3.0 … 2.0 0.0 0.0 2577 4.0 3.0 3.0 … 2.0 0.0 0.0 2578 4.0 2.0 3.0 … 2.0 0.0 0.0
[2579 rows x 21 columns] |
As we conclude this phase on implementing ordinal encoding, we’ve got set the stage for a sturdy evaluation. By meticulously mapping every ordinal characteristic to its intrinsic hierarchical worth, we empower our predictive fashions to grasp higher and leverage the structured relationships inherent within the information. The cautious consideration to the encoding element paves the best way for extra insightful and exact modeling.
Visualizing Determination Timber: Insights from Ordinally Encoded Knowledge
Within the remaining a part of this publish, we’ll delve into how a Determination Tree Regressor interprets and makes use of this fastidiously encoded information. We are going to visually discover the decision-making strategy of the tree, highlighting how the ordinal nature of our options influences the paths and choices throughout the mannequin. This visible depiction is not going to solely affirm the significance of right information preparation but additionally illuminate the mannequin’s reasoning in a tangible means. With the explicit variables now thoughtfully preprocessed and encoded, our dataset is primed for the following essential step: coaching the Determination Tree Regressor:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# Constructing on the above blocks of code # Import the required libraries from sklearn.tree import DecisionTreeRegressor from sklearn.model_selection import train_test_split import dtreeviz
# Load and cut up the info X_ordinal = Ames_ordinal_encoded # Use solely the ordinal options for becoming the mannequin y = Ames[‘SalePrice’] X_train, X_test, y_train, y_test = train_test_split(X_ordinal, y, test_size=0.2, random_state=42)
# Initialize and match the Determination Tree tree_model = DecisionTreeRegressor(max_depth=3) tree_model.match(X_train.values, y_train)
# Visualize the choice tree utilizing dtreeviz viz = dtreeviz.mannequin(tree_model, X_train, y_train, target_name=‘SalePrice’, feature_names=X_train.columns.tolist())
# In Jupyter Pocket book, you possibly can straight view the visible utilizing the beneath: # viz.view() # Renders and shows the SVG visualization
# In PyCharm, you possibly can render and show the SVG picture: v = viz.view() # render as SVG into inner object v.present() # pop up window |
By visualizing the choice tree, we offer a graphical illustration of how our mannequin processes options to reach at predictions:
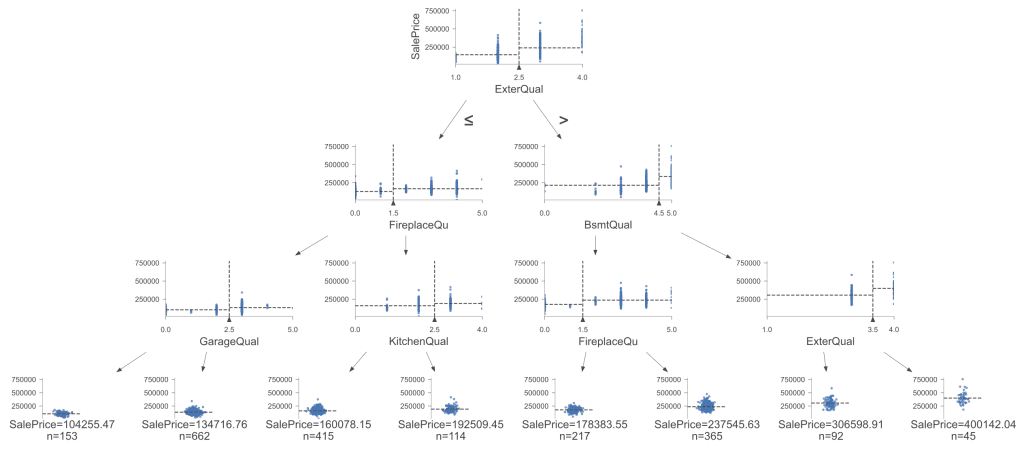
Visualized determination tree. Click on to enlarge.
The options chosen for the splits on this tree embody ‘ExterQual’, ‘FireplaceQu’, ‘BsmtQual’, and ‘GarageQual’, and ‘KitchenQual’. These options had been chosen based mostly on their means to scale back the MSE when used to separate the info. The degrees or thresholds for these splits (e.g., ExterQual <= 2.5) had been decided throughout the coaching course of to optimize the separation of knowledge factors into extra homogeneous teams. This visualization not solely confirms the efficacy of our encoding technique but additionally showcases the strategic depth that call timber deliver to predictive modeling.
Additional Studying
APIs
Tutorials
Ames Housing Dataset & Knowledge Dictionary
Abstract
On this publish, you examined the excellence between ordinal and nominal categorical variables. By implementing ordinal encoding utilizing Python and the OrdinalEncoder from sklearn, you’ve ready the Ames dataset in a means that respects the inherent order of the info. Lastly, you’ve seen firsthand how visualizing determination timber with this encoded information supplies tangible insights, providing a clearer perspective on how fashions predict based mostly on the options you present.
Particularly, you discovered:
- Basic Distinctions in Categorical Variables: Understanding the distinction between ordinal and nominal variables.
- Mannequin-Particular Preprocessing Wants: Completely different fashions, like linear regressor and determination timber, require tailor-made preprocessing of categorical information to optimize their efficiency.
- Handbook Specification in Ordinal Encoding: The utilization of “classes” within the
OrdinalEncoderto customise your encoding technique.
Do you could have any questions? Please ask your questions within the feedback beneath, and I’ll do my finest to reply.
Get Began on The Newbie’s Information to Knowledge Science!

Study the mindset to turn into profitable in information science tasks
…utilizing solely minimal math and statistics, purchase your ability via brief examples in Python
Uncover how in my new Book:
The Newbie’s Information to Knowledge Science
It supplies self-study tutorials with all working code in Python to show you from a novice to an knowledgeable. It reveals you learn how to discover outliers, affirm the normality of knowledge, discover correlated options, deal with skewness, test hypotheses, and rather more…all to help you in making a narrative from a dataset.