

{kind=link}
After Meta, OpenAI, Microsoft, and Google – Alibaba Group is within the race for AI improvement to ease human life. Lately, Alibaba Group introduced a brand new AI mannequin, “EMO AI” – The Emote Portrait Alive. The thrilling a part of this mannequin is that it could possibly animate a single portrait picture and generate movies (speaking or singing).
The current strides in picture technology, significantly Diffusion Fashions, have set new requirements in realism. Majorly, AI fashions akin to Sora, DALL-E 3, and others are developed on the Diffusion mannequin. The Diffusion Fashions have considerably superior, with their impression extending to video technology. Whereas these fashions excel in creating high-quality photos, their potential in crafting dynamic visible narratives has spurred curiosity in video technology. A selected focus has been on producing human-centric movies, akin to speaking head, which goals to authentically replicate facial expressions from supplied audio clips. The EMO AI mannequin is an modern framework sidestepping 3D fashions, immediately synthesizing audio-to-video for expressive and lifelike animations. On this weblog, you’ll study all about EMO AI by Alibaba.
Learn on!

What’s EMO AI by Alibaba?
Conventional strategies usually fail to seize the total spectrum of human expressions and the individuality of particular person facial types,”. “To deal with these points, we suggest EMO, a novel framework that makes use of a direct audio-to-video synthesis strategy, bypassing the necessity for intermediate 3D fashions or facial landmarks.
Lead Writer Linrui Tian
EMO, quick for Emote Portrait Alive, is an modern system researchers at Alibaba Group developed. It brings collectively synthetic intelligence and video manufacturing, leading to exceptional capabilities. Right here’s what EMO can do:
- Animating Portraits: EMO AI can take a single portrait picture and breathe life into it. It generates lifelike movies of the individual depicted within the picture, making them seem as if they’re speaking or singing.
- Audio-to-Video Synthesis: In contrast to conventional strategies that depend on intermediate 3D fashions or facial landmarks, EMO AI immediately synthesizes video from audio cues. This strategy ensures seamless body transitions and constant id preservation, producing extremely expressive and reasonable animations.
- Expressive Facial Expressions: EMO AI captures the dynamic and nuanced relationship between audio cues and facial actions. It goes past static expressions, permitting for a large spectrum of human feelings and particular person facial types.
- Versatility: EMO AI can generate convincing talking and singing movies in varied types. Whether or not it’s a heartfelt dialog or a melodious music, EMO AI brings it to life.
EMO is a groundbreaking development that synchronizes lips with sounds in photographs, creating fluid and expressive animations that captivate viewers. Think about turning a nonetheless portrait right into a vigorous, speaking, or singing avatar—EMO makes it attainable!
Additionally learn: Exploring Diffusion Fashions in NLP Past GANs and VAEs
EMO AI Coaching
Alibaba’s EMO AI is an expressive audio-driven portrait-video technology framework syntheses character head movies from photos and audio clips. This eliminates the necessity for intermediate representations, guaranteeing excessive visible and emotional constancy aligned with the audio enter. EMO leverages Diffusion Fashions to generate character head movies to seize nuanced micro-expressions and facilitate pure head actions.
To coach EMO, researchers curated a various audio-video dataset exceeding 250 hours of footage and 150 million photos. This dataset covers varied content material varieties, together with speeches, movie and tv clips, and singing performances in a number of languages. The richness of content material ensures that EMO captures a variety of human expressions and vocal types, offering a sturdy basis for its improvement.
The EMO AI Methodology
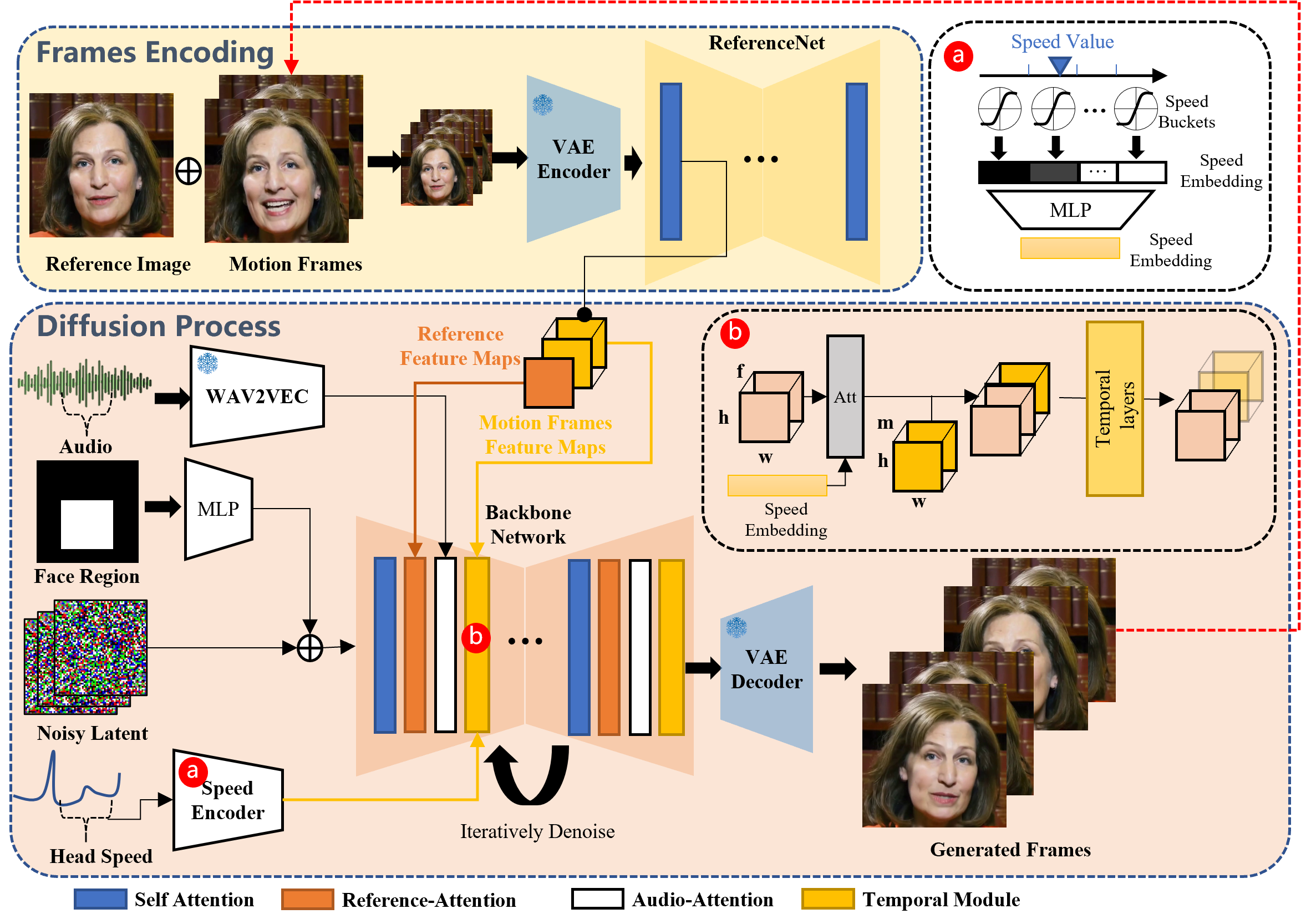
EMO’s framework contains two primary phases – body encoding and the Diffusion course of. Within the Frames Encoding stage, ReferenceNet extracts options from the reference picture and movement frames. The Diffusion Course of includes a pretrained audio encoder, facial area masks integration, and denoising operations facilitated by the Spine Community. Consideration mechanisms, together with Reference-Consideration and Audio-Consideration, protect id and modulate actions. Temporal Modules manipulate the temporal dimension, adjusting movement velocity for a seamless and expressive video technology course of.
To keep up consistency with the enter reference picture, EMO enhances the strategy of ReferenceNet by introducing a FrameEncoding module. This module ensures the character’s id is preserved all through the video technology course of, contributing to the realism of the ultimate output.
Integrating audio with Diffusion Fashions presents challenges because of the inherent ambiguity in mapping audio to facial features. To deal with this, EMO incorporates steady management mechanisms – a pace controller and a face area controller – enhancing stability throughout video technology with out compromising range. The steadiness is essential to stop facial distortions or jittering between frames.
Additionally learn: Unraveling the Energy of Diffusion Fashions in Fashionable AI
The Qualitative Comparisons
Within the determine, you’ll find the visible comparability between the EMO technique and former approaches. When given a single reference picture, Wav2Lip usually produces movies with blurry mouth areas and static head poses, missing eye motion. DreamTalk’s equipped type clips could distort unique faces, limiting facial expressions and head motion dynamism. In distinction, the EMO technique outperforms SadTalker and DreamTalk by producing a broader vary of head actions and dynamic facial expressions. The EMO strategy doesn’t make the most of audio-driven character movement with out counting on direct indicators like mix shapes or 3DMM.
Outcomes and Efficiency
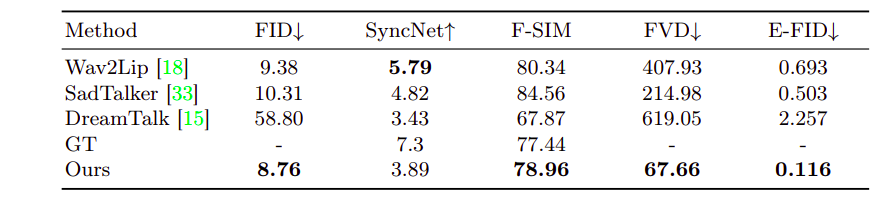
EMO’s efficiency was evaluated on the HDTF dataset, surpassing present state-of-the-art strategies akin to DreamTalk, Wav2Lip, and SadTalker throughout a number of metrics. Quantitative assessments showcased EMO’s superiority, together with FID, SyncNet, F-SIM, and FVD. Consumer research and qualitative evaluations additional demonstrated EMO’s potential to generate pure and expressive speaking and singing movies, marking it because the main resolution within the subject.
Right here is the Github hyperlink: EMO AI
Challenges with the Conventional Methodology
Conventional strategies in speaking head video technology usually impose constraints on the output, limiting the richness of facial expressions. Methods like utilizing 3D fashions or extracting head motion sequences from base movies simplify the duty however compromise naturalness. EMO goals to create an modern framework that captures a broad spectrum of reasonable facial expressions and facilitates pure head actions.
Test Out These Movies by EMO AI
Listed below are the current movies by EMO AI:
Cross-Actor Efficiency
Character: Joaquin Rafael Phoenix – The Jocker – Jocker 2019
Vocal Supply: The Darkish Knight 2008
Character: AI lady generated by xxmix_9realisticSDXL
Vocal Supply: Movies printed by itsjuli4.
Speaking With Totally different Characters
Character: Audrey Kathleen Hepburn-Ruston
Vocal Supply: Interview Clip
Character: Mona Lisa
Vocal Supply: Shakespeare’s Monologue II As You Like It: Rosalind “Sure, one; and on this method.”
Speedy Rhythm
Character: Leonardo Wilhelm DiCaprio
Vocal Supply: EMINEM – GODZILLA (FT. JUICE WRLD) COVER
Character: KUN KUN
Vocal Supply: Eminem – Rap God
Totally different Language & Portrait Model
Character: AI Lady generated by ChilloutMix
Vocal Supply: David Tao – Melody. Coated by NINGNING (mandarin)
Character: AI lady generated by WildCardX-XL-Fusion
Vocal Supply: JENNIE – SOLO. Cowl by Aiana (Korean)
Make Portrait Sing
Character: AI Mona Lisa generated by dreamshaper XL
Vocal Supply: Miley Cyrus – Flowers. Coated by YUQI
Character: AI Girl from SORA
Vocal Supply: Dua Lipa – Don’t Begin Now
Limitations of the EMO Mannequin
Listed below are the constraints:
- Time Consumption: The tactic employed has sure limitations, with one key disadvantage being its elevated time requirement in comparison with various approaches not reliant on diffusion fashions.
- Unintended Physique Half Technology: One other limitation lies within the absence of express management indicators for steering the character’s movement. This absence could result in the unintended technology of further physique components, like fingers, inflicting artifacts within the ensuing video.
One potential resolution to handle the inadvertent physique half technology includes implementing management indicators devoted to every physique half.
Conclusion
EMO by Alibaba emerges as a groundbreaking resolution in speaking head video technology, introducing an modern framework that immediately synthesizes expressive character head movies from audio and reference photos. Integrating Diffusion Fashions, steady management mechanisms, and identity-preserving modules ensures a extremely reasonable and expressive end result. As the sphere progresses, Alibaba AI EMO is a testomony to the transformative energy of audio-driven portrait-video technology.
You can even learn: Sora AI: New-Gen Textual content-to-Video Device by OpenAI