

{kind=link}
A vector database is a group of information the place each bit of information is saved as a (numerical) vector. A vector represents an object or entity, comparable to a picture, individual, place and many others. within the summary N-dimensional area.
Vectors, as defined within the earlier chapter, are essential for figuring out how entities are associated and can be utilized to seek out their semantic similarity. This may be utilized in a number of methods for search engine optimization – comparable to grouping comparable key phrases or content material (utilizing kNN).
On this article, we’re going to study a couple of methods to use AI to search engine optimization, together with discovering semantically comparable content material for inner linking. This may help you refine your content material technique in an period the place engines like google more and more depend on LLMs.
It’s also possible to learn a earlier article on this collection about easy methods to discover key phrase cannibalization utilizing OpenAI’s textual content embeddings.
Let’s dive in right here to begin constructing the premise of our software.
Understanding Vector Databases
In case you have 1000’s of articles and need to discover the closest semantic similarity to your goal question, you’ll be able to’t create vector embeddings for all of them on the fly to check, as it’s extremely inefficient.
For that to occur, we would want to generate vector embeddings solely as soon as and hold them in a database we will question and discover the closest match article.
And that’s what vector databases do: They’re particular sorts of databases that retailer embeddings (vectors).
While you question the database, not like conventional databases, they carry out cosine similarity match and return vectors (on this case articles) closest to a different vector (on this case a key phrase phrase) being queried.
Here’s what it appears to be like like:
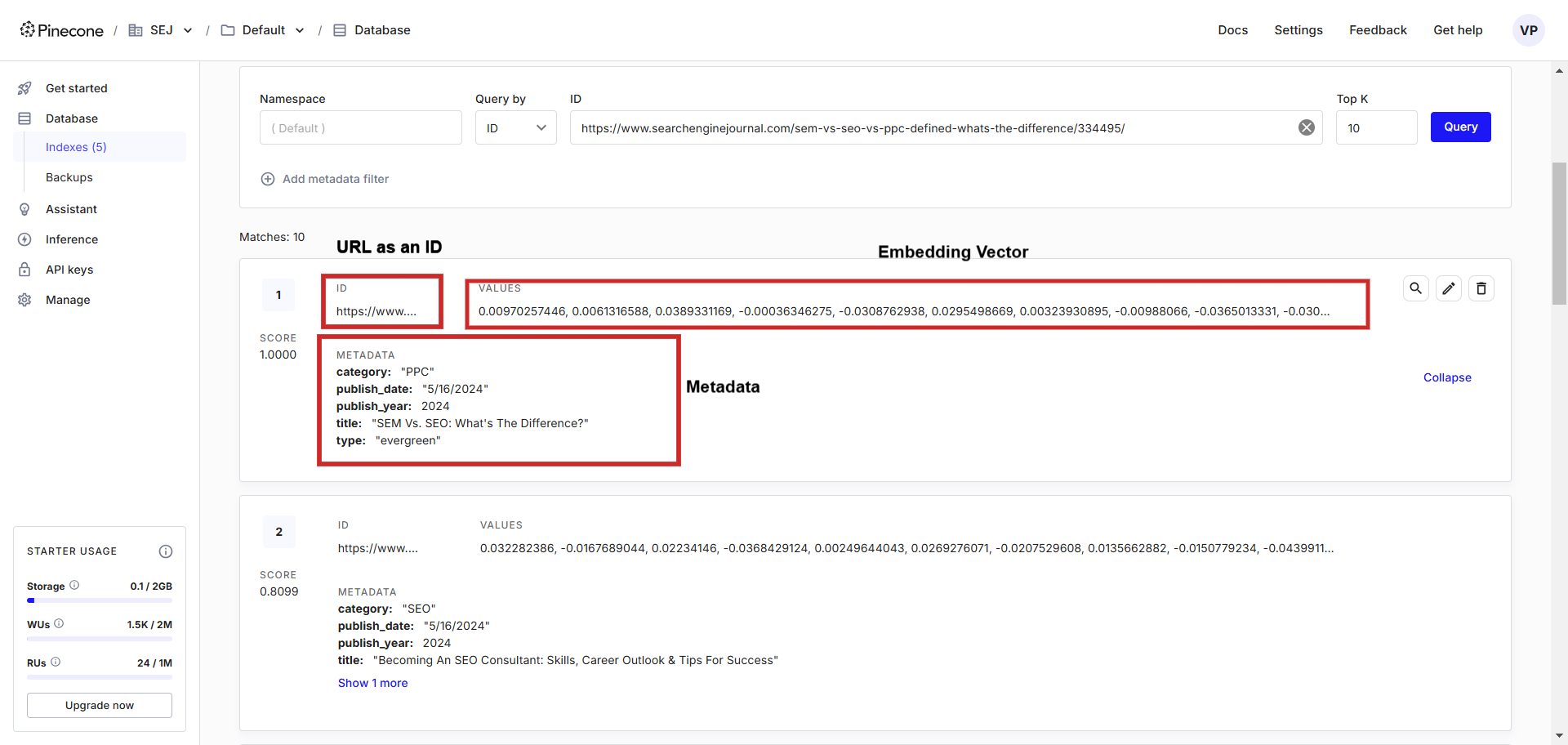 Textual content embedding file instance within the vector database.
Textual content embedding file instance within the vector database.Within the vector database, you’ll be able to see vectors alongside metadata saved, which we will simply question utilizing a programming language of our selection.
On this article, we shall be utilizing Pinecone because of its ease of understanding and ease of use, however there are different suppliers comparable to Chroma, BigQuery, or Qdrant it’s possible you’ll need to try.
Let’s dive in.
1. Create A Vector Database
First, register an account at Pinecone and create an index with a configuration of “text-embedding-ada-002” with ‘cosine’ as a metric to measure vector distance. You possibly can identify the index something, we are going to identify itarticle-index-all-ada‘.
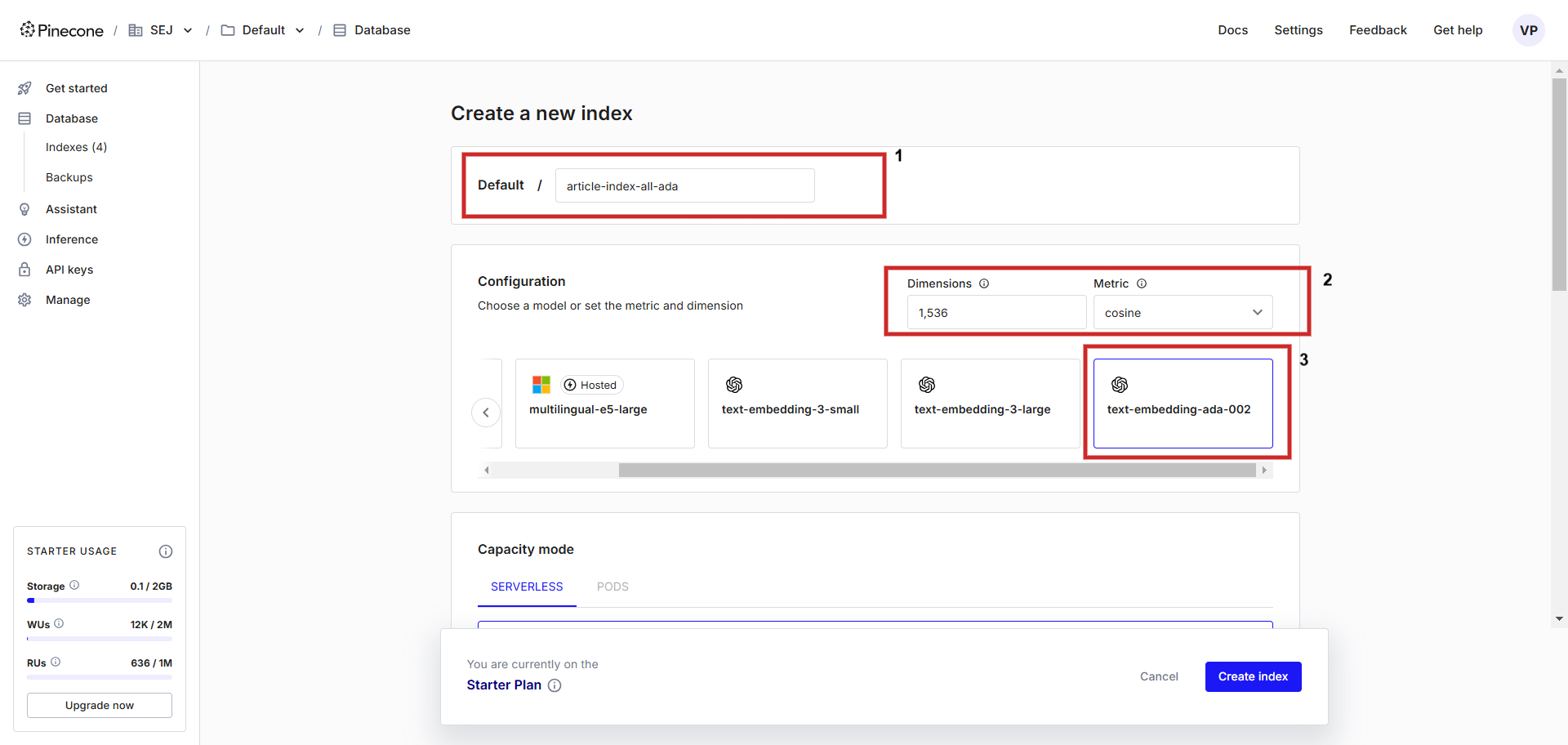 Making a vector database.
Making a vector database.This helper UI is just for aiding you in the course of the setup, in case you need to retailer Vertex AI vector embedding it is advisable set ‘dimensions’ to 768 within the config display screen manually to match default dimensionality and you may retailer Vertex AI textual content vectors (you’ll be able to set dimension worth something from 1 to 768 to avoid wasting reminiscence).
On this article we are going to learn to use OpenAi’s ‘text-embedding-ada-002’ and Google’s Vertex AI ‘text-embedding-005’ fashions.
As soon as created, we want an API key to have the ability to connect with the database utilizing a bunch URL of the vector database.
Subsequent, you have to to make use of Jupyter Pocket book. When you don’t have it put in, comply with this information to put in it and run this command (beneath) afterward in your PC’s terminal to put in all mandatory packages.
pip set up openai google-cloud-aiplatform google-auth pandas pinecone-client tabulate ipython numpyAnd keep in mind ChatGPT may be very helpful while you encounter points throughout coding!
2. Export Your Articles From Your CMS
Subsequent, we have to put together a CSV export file of articles out of your CMS. When you use WordPress, you should use a plugin to do custom-made exports.
As our final aim is to construct an inner linking software, we have to determine which knowledge must be pushed to the vector database as metadata. Primarily, metadata-based filtering acts as an extra layer of retrieval steerage, aligning it with the final RAG framework by incorporating exterior information, which can assist to enhance retrieval high quality.
As an illustration, if we’re modifying an article on “PPC” and need to insert a hyperlink to the phrase “Key phrase Analysis,” we will specify in our software that “Class=PPC.” This can permit the software to question solely articles throughout the “PPC” class, making certain correct and contextually related linking, or we might need to hyperlink to the phrase “most up-to-date google replace” and restrict the match solely to information articles through the use of ‘Kind’ and printed this 12 months.
In our case, we shall be exporting:
- Title.
Class. - Kind.
- Publish Date.
- Publish 12 months.
- Permalink.
- Meta Description.
- Content material.
To assist return the perfect outcomes, we might concatenate the title and meta descriptions fields as they’re the perfect illustration of the article that we will vectorize and excellent for embedding and inner linking functions.
Utilizing the complete article content material for embeddings might scale back precision and dilute the relevance of the vectors.
This occurs as a result of a single massive embedding tries to symbolize a number of matters lined within the article without delay, resulting in a much less centered and related illustration. Chunking methods (splitting the article by pure headings or semantically significant segments) have to be utilized, however these usually are not the main target of this text.
Right here’s the pattern export file you’ll be able to obtain and use for our code pattern beneath.
2. Inserting OpenAi’s Textual content Embeddings Into The Vector Database
Assuming you have already got an OpenAI API key, this code will generate vector embeddings from the textual content and insert them into the vector database in Pinecone.
import pandas as pd
from openai import OpenAI
from pinecone import Pinecone
from IPython.show import clear_output
# Setup your OpenAI and Pinecone API keys
openai_client = OpenAI(api_key='YOUR_OPENAI_API_KEY') # Instantiate OpenAI shopper
pinecone = Pinecone(api_key='YOUR_PINECON_API_KEY')
# Connect with an current Pinecone index
index_name = "article-index-all-ada"
index = pinecone.Index(index_name)
def generate_embeddings(textual content):
"""
Generates an embedding for the given textual content utilizing OpenAI's API.
Returns None if textual content is invalid or an error happens.
"""
attempt:
if not textual content or not isinstance(textual content, str):
elevate ValueError("Enter textual content should be a non-empty string.")
consequence = openai_client.embeddings.create(
enter=textual content,
mannequin="text-embedding-ada-002"
)
clear_output(wait=True) # Clear output for a contemporary show
if hasattr(consequence, 'knowledge') and len(consequence.knowledge) > 0:
print("API Response:", consequence)
return consequence.knowledge[0].embedding
else:
elevate ValueError("Invalid response from the OpenAI API. No knowledge returned.")
besides ValueError as ve:
print(f"ValueError: {ve}")
return None
besides Exception as e:
print(f"An error occurred whereas producing embeddings: {e}")
return None
# Load your articles from a CSV
df = pd.read_csv('Pattern Export File.csv')
# Course of every article
for idx, row in df.iterrows():
attempt:
clear_output(wait=True)
content material = row["Content"]
vector = generate_embeddings(content material)
if vector is None:
print(f"Skipping article ID {row['ID']} because of empty or invalid embedding.")
proceed
index.upsert(vectors=[
(
row['Permalink'], # Distinctive ID
vector, # The embedding
{
'title': row['Title'],
'class': row['Category'],
'kind': row['Type'],
'publish_date': row['Publish Date'],
'publish_year': row['Publish Year']
}
)
])
besides Exception as e:
clear_output(wait=True)
print(f"Error processing article ID {row['ID']}: {str(e)}")
print("Embeddings are efficiently saved within the vector database.")
You could create a pocket book file and duplicate and paste it in there, then add the CSV file ‘Pattern Export File.csv’ in the identical folder.
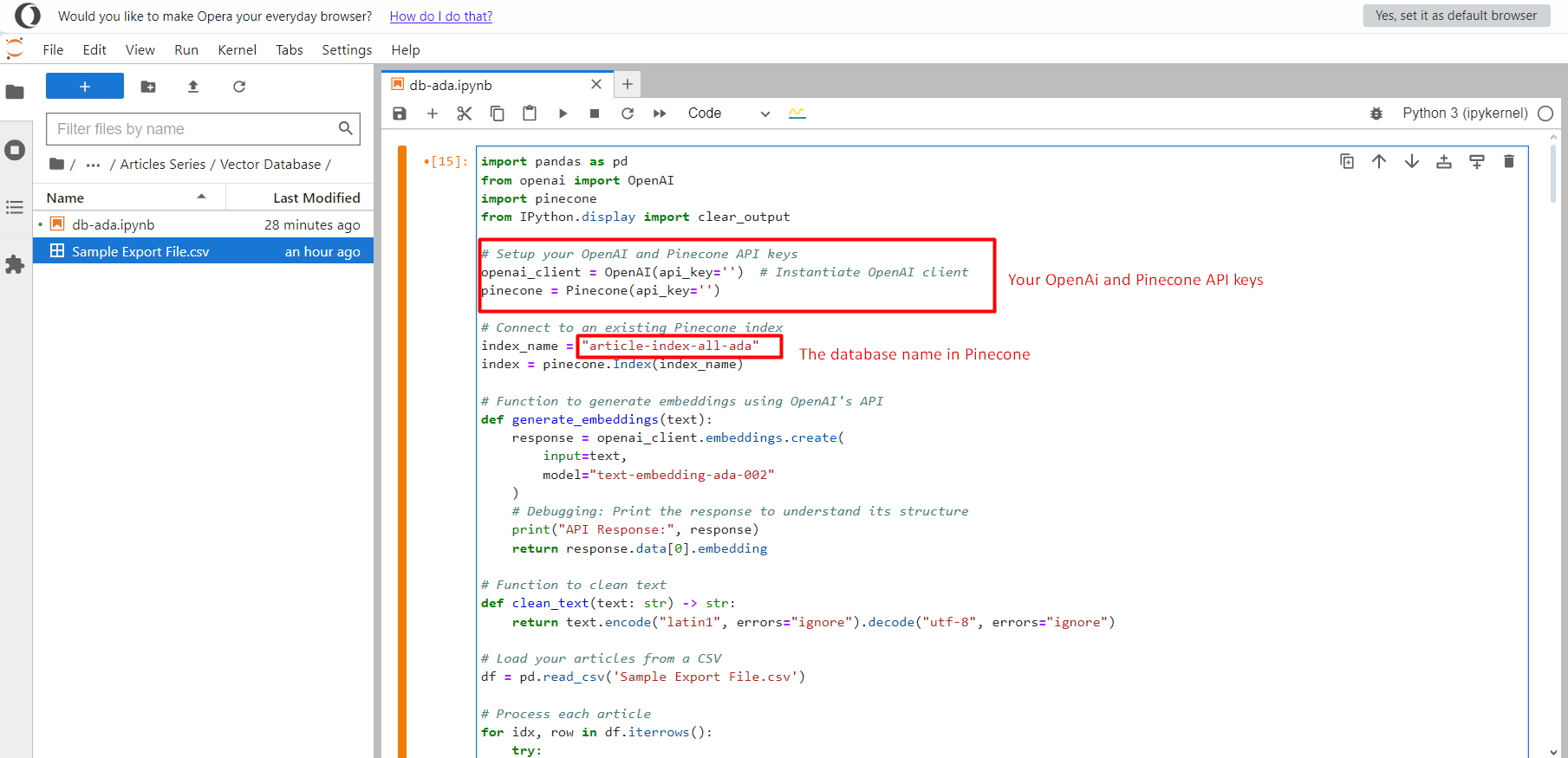 Jupyter mission.
Jupyter mission.As soon as carried out, click on on the Run button and it’ll begin pushing all textual content embedding vectors into the index article-index-all-ada we created in step one.
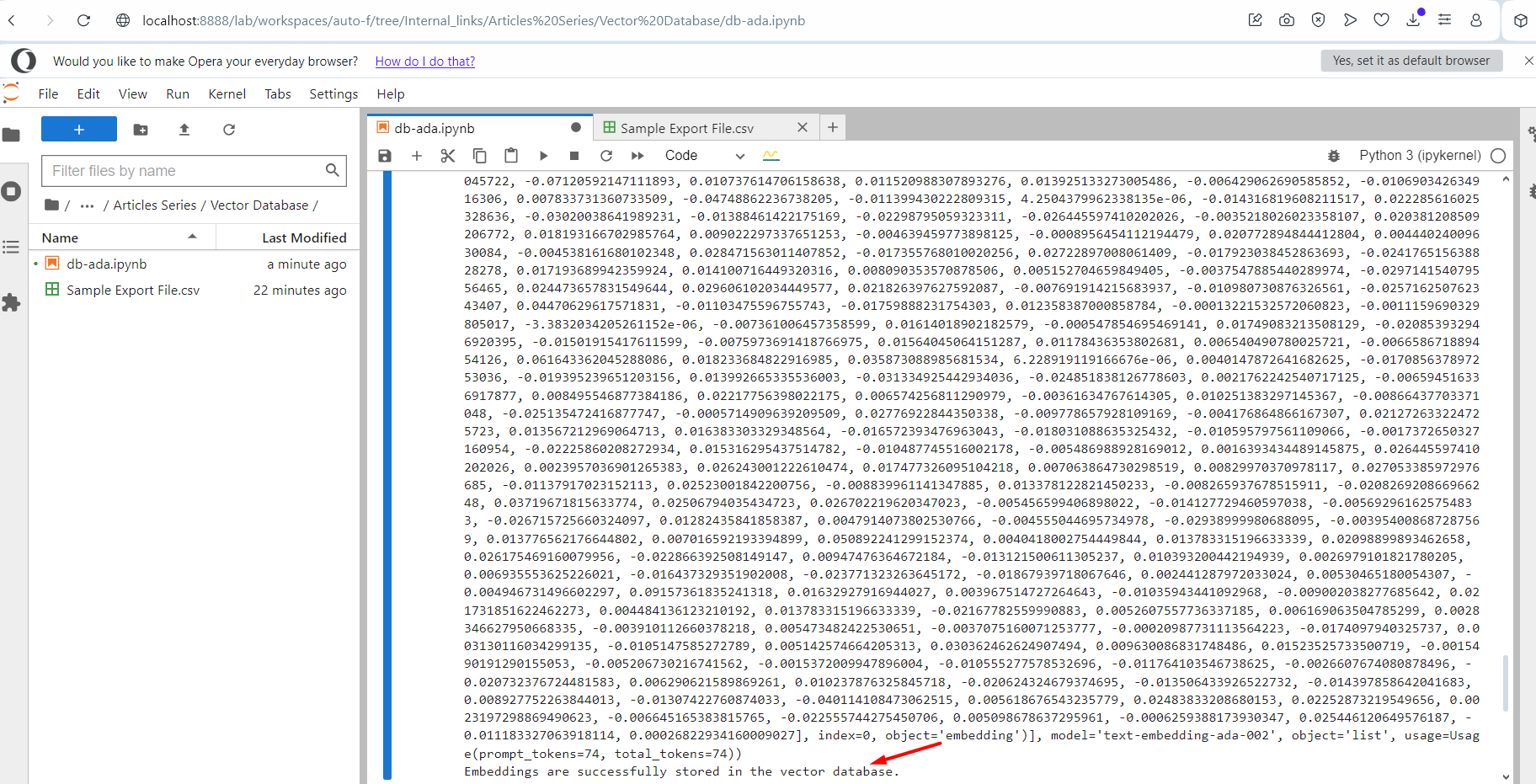 Operating the script.
Operating the script.You will note an output log textual content of embedding vectors. As soon as completed, it can present the message on the finish that it was efficiently completed. Now go and verify your index within the Pinecone and you will notice your information are there.
3. Discovering An Article Match For A Key phrase
Okay now, let’s attempt to discover an article match for the Key phrase.
Create a brand new pocket book file and duplicate and paste this code.
from openai import OpenAI
from pinecone import Pinecone
from IPython.show import clear_output
from tabulate import tabulate # Import tabulate for desk formatting
# Setup your OpenAI and Pinecone API keys
openai_client = OpenAI(api_key='YOUR_OPENAI_API_KEY') # Instantiate OpenAI shopper
pinecone = Pinecone(api_key='YOUR_OPENAI_API_KEY')
# Connect with an current Pinecone index
index_name = "article-index-all-ada"
index = pinecone.Index(index_name)
# Operate to generate embeddings utilizing OpenAI's API
def generate_embeddings(textual content):
"""
Generates an embedding for a given textual content utilizing OpenAI's API.
"""
attempt:
if not textual content or not isinstance(textual content, str):
elevate ValueError("Enter textual content should be a non-empty string.")
consequence = openai_client.embeddings.create(
enter=textual content,
mannequin="text-embedding-ada-002"
)
# Debugging: Print the response to grasp its construction
clear_output(wait=True)
#print("API Response:", consequence)
if hasattr(consequence, 'knowledge') and len(consequence.knowledge) > 0:
return consequence.knowledge[0].embedding
else:
elevate ValueError("Invalid response from the OpenAI API. No knowledge returned.")
besides ValueError as ve:
print(f"ValueError: {ve}")
return None
besides Exception as e:
print(f"An error occurred whereas producing embeddings: {e}")
return None
# Operate to question the Pinecone index with key phrases and metadata
def match_keywords_to_index(key phrases):
"""
Matches a listing of key phrases to the closest article within the Pinecone index, filtering by metadata dynamically.
"""
outcomes = []
for keyword_pair in key phrases:
attempt:
clear_output(wait=True)
# Extract the key phrase and class from the sub-array
key phrase = keyword_pair[0]
class = keyword_pair[1]
# Generate embedding for the present key phrase
vector = generate_embeddings(key phrase)
if vector is None:
print(f"Skipping key phrase '{key phrase}' because of embedding error.")
proceed
# Question the Pinecone index for the closest vector with metadata filter
query_results = index.question(
vector=vector, # The embedding of the key phrase
top_k=1, # Retrieve solely the closest match
include_metadata=True, # Embrace metadata within the outcomes
filter={"class": class} # Filter outcomes by metadata class dynamically
)
# Retailer the closest match
if query_results['matches']:
closest_match = query_results['matches'][0]
outcomes.append({
'Key phrase': key phrase, # The searched key phrase
'Class': class, # The class used for filtering
'Match Rating': f"{closest_match['score']:.2f}", # Similarity rating (formatted to 2 decimal locations)
'Title': closest_match['metadata'].get('title', 'N/A'), # Title of the article
'URL': closest_match['id'] # Utilizing 'id' because the URL
})
else:
outcomes.append({
'Key phrase': key phrase,
'Class': class,
'Match Rating': 'N/A',
'Title': 'No match discovered',
'URL': 'N/A'
})
besides Exception as e:
clear_output(wait=True)
print(f"Error processing key phrase '{key phrase}' with class '{class}': {e}")
outcomes.append({
'Key phrase': key phrase,
'Class': class,
'Match Rating': 'Error',
'Title': 'Error occurred',
'URL': 'N/A'
})
return outcomes
# Instance utilization: Discover matches for an array of key phrases and classes
key phrases = [["SEO Tools", "SEO"], ["TikTok", "TikTok"], ["SEO Consultant", "SEO"]] # Substitute along with your key phrases and classes
matches = match_keywords_to_index(key phrases)
# Show the ends in a desk
print(tabulate(matches, headers="keys", tablefmt="fancy_grid"))
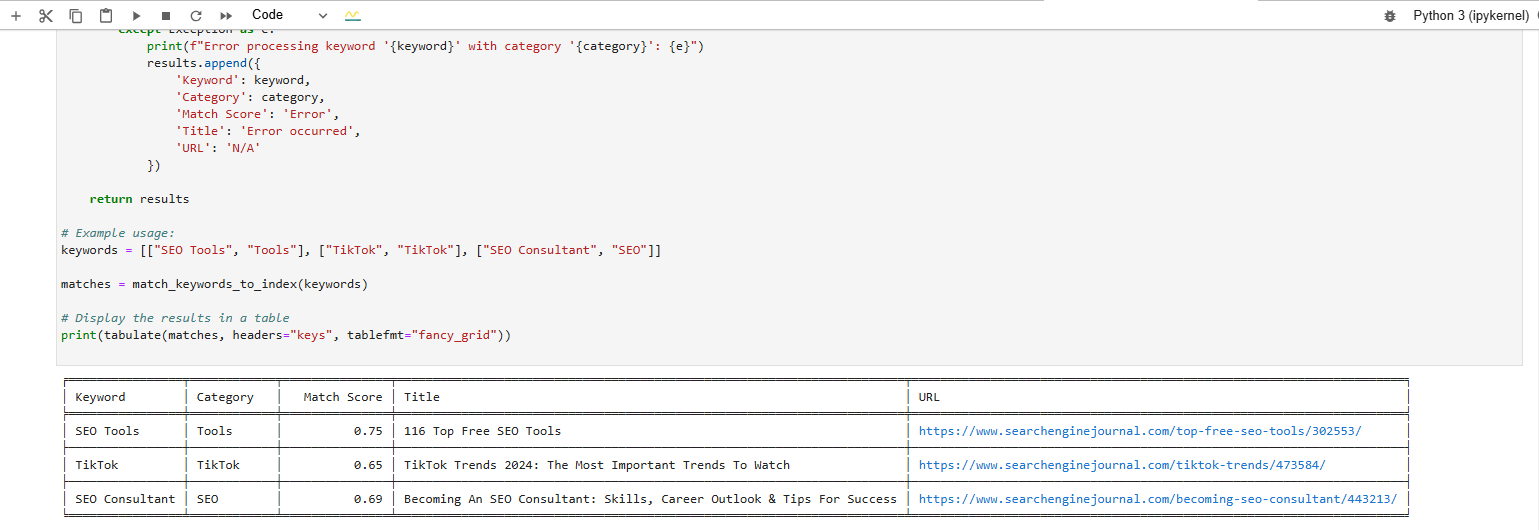
We’re looking for a match for these key phrases:
- search engine optimization Instruments.
- TikTok.
- search engine optimization Advisor.
And that is the consequence we get after executing the code:
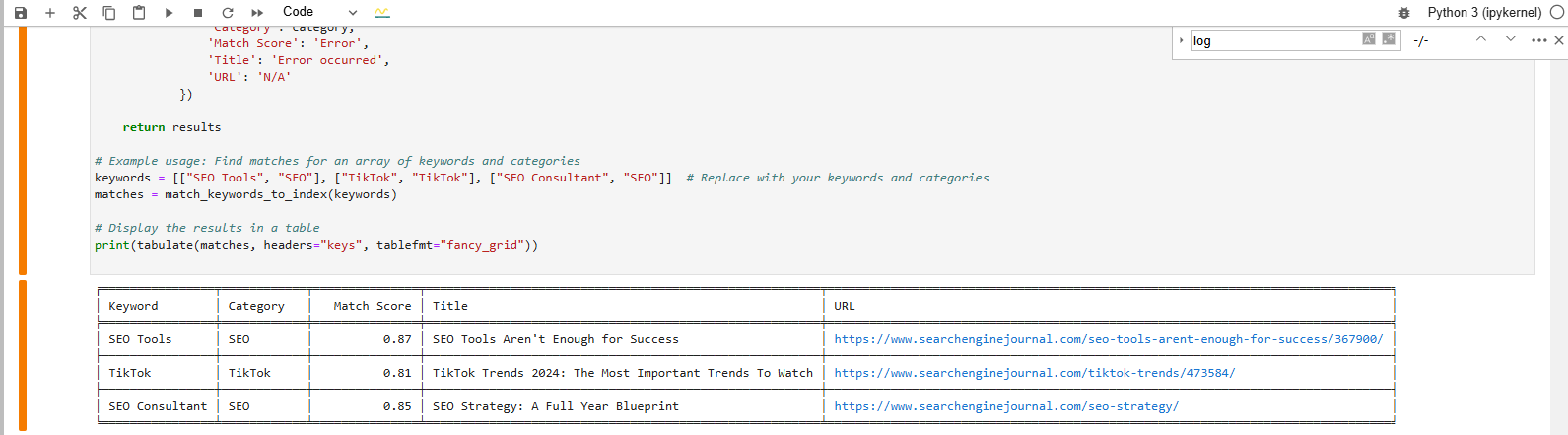 Discover a match for the key phrase phrase from vector database
Discover a match for the key phrase phrase from vector databaseThe desk formatted output on the backside reveals the closest article matches to our key phrases.
4. Inserting Google Vertex AI Textual content Embeddings Into The Vector Database
Now let’s do the identical however with Google Vertex AI ‘text-embedding-005’embedding. This mannequin is notable as a result of it’s developed by Google, powers Vertex AI Search, and is particularly educated to deal with retrieval and query-matching duties, making it well-suited for our use case.
You possibly can even construct an inner search widget and add it to your web site.
Begin by signing in to Google Cloud Console and create a mission. Then from the API library discover Vertex AI API and allow it.
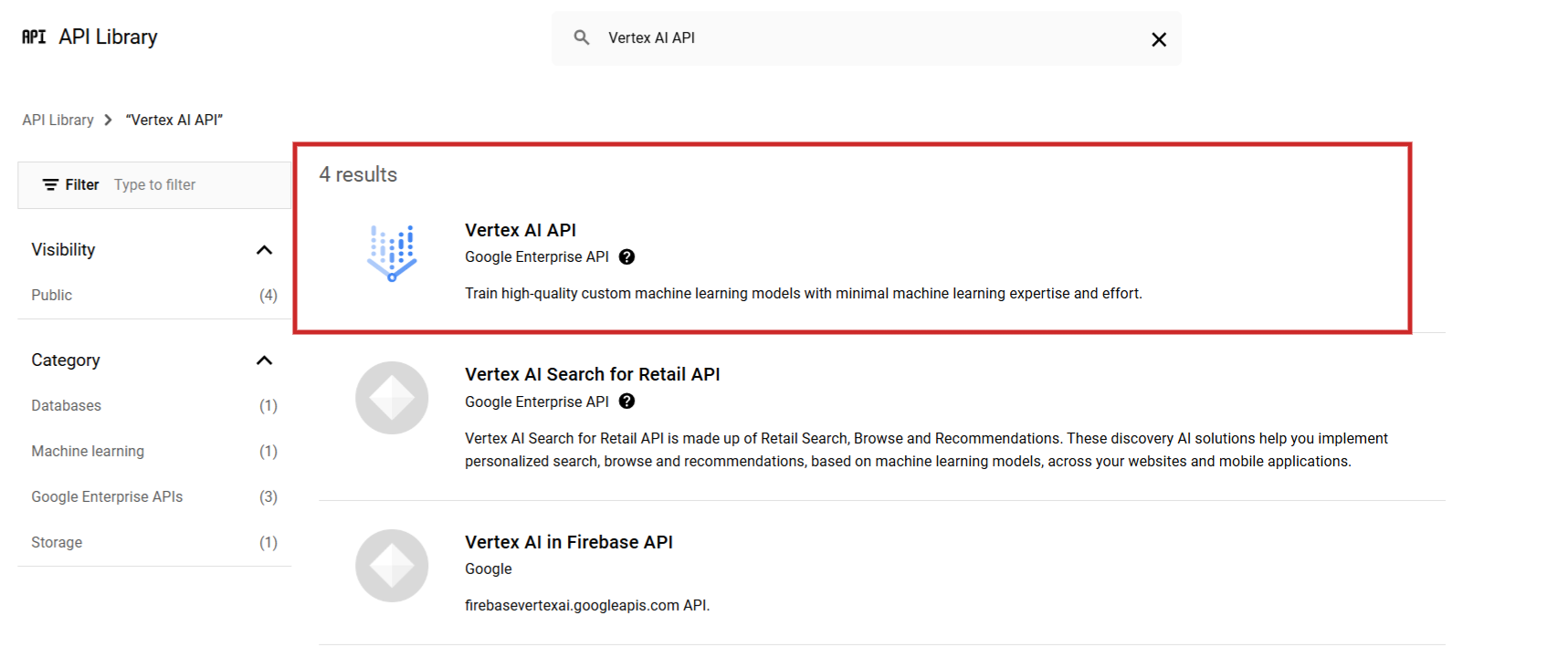 Screenshot from Google Cloud Console, December 2024
Screenshot from Google Cloud Console, December 2024Arrange your billing account to have the ability to use Vertex AI as pricing is $0.0002 per 1,000 characters (and it presents $300 credit for brand spanking new customers).
When you set it, it is advisable navigate to API Companies > Credentials create a service account, generate a key, and obtain them as JSON.
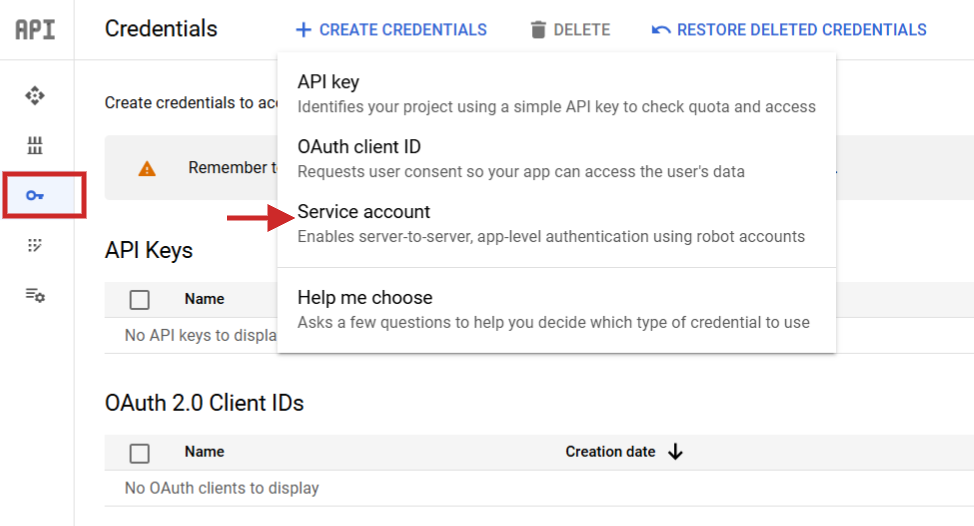
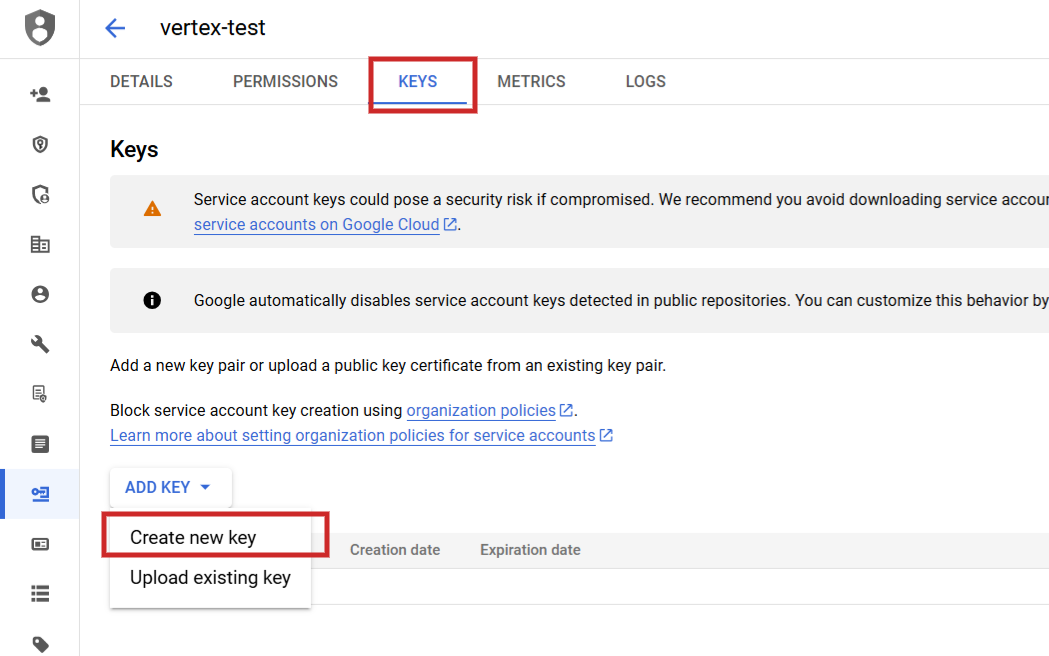

Rename the JSON file to config.json and add it (by way of the arrow up icon) to your Jupyter Pocket book mission folder.
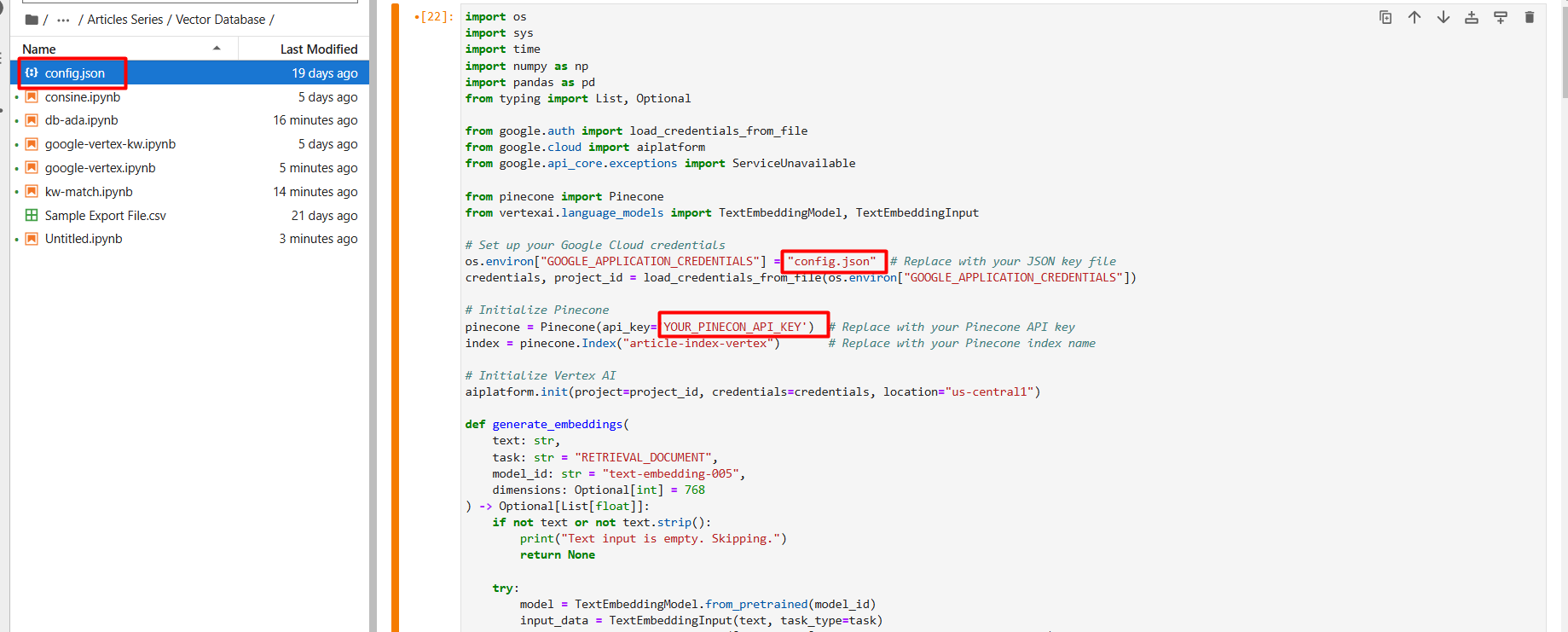 Screenshot from Google Cloud Console, December 2024
Screenshot from Google Cloud Console, December 2024Within the setup first step, create a brand new vector database referred to as article-index-vertex by setting dimension 768 manually.
As soon as created you’ll be able to run this script to begin producing vector embeddings from the the identical pattern file utilizing Google Vertex AI text-embedding-005 mannequin (you’ll be able to select text-multilingual-embedding-002 you probably have non-English textual content).
import os
import sys
import time
import numpy as np
import pandas as pd
from typing import Checklist, Non-obligatory
from google.auth import load_credentials_from_file
from google.cloud import aiplatform
from google.api_core.exceptions import ServiceUnavailable
from pinecone import Pinecone
from vertexai.language_models import TextEmbeddingModel, TextEmbeddingInput
# Arrange your Google Cloud credentials
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "config.json" # Substitute along with your JSON key file
credentials, project_id = load_credentials_from_file(os.environ["GOOGLE_APPLICATION_CREDENTIALS"])
# Initialize Pinecone
pinecone = Pinecone(api_key='YOUR_PINECON_API_KEY') # Substitute along with your Pinecone API key
index = pinecone.Index("article-index-vertex") # Substitute along with your Pinecone index identify
# Initialize Vertex AI
aiplatform.init(mission=project_id, credentials=credentials, location="us-central1")
def generate_embeddings(
textual content: str,
activity: str = "RETRIEVAL_DOCUMENT",
model_id: str = "text-embedding-005",
dimensions: Non-obligatory[int] = 768
) -> Non-obligatory[List[float]]:
if not textual content or not textual content.strip():
print("Textual content enter is empty. Skipping.")
return None
attempt:
mannequin = TextEmbeddingModel.from_pretrained(model_id)
input_data = TextEmbeddingInput(textual content, task_type=activity)
vectors = mannequin.get_embeddings([input_data], output_dimensionality=dimensions)
return vectors[0].values
besides ServiceUnavailable as e:
print(f"Vertex AI service is unavailable: {e}")
return None
besides Exception as e:
print(f"Error producing embeddings: {e}")
return None
# Load knowledge from CSV
knowledge = pd.read_csv("Pattern Export File.csv") # Substitute along with your CSV file path
for idx, row in knowledge.iterrows():
attempt:
permalink = str(row["Permalink"])
content material = row["Content"]
embedding = generate_embeddings(content material)
if not embedding:
print(f"Skipping article ID {row['ID']} because of empty or failed embedding.")
proceed
print(f"Embedding for {permalink}: {embedding[:5]}...")
sys.stdout.flush()
index.upsert(vectors=[
(
permalink,
embedding,
{
'category': row['Category'],
'title': row['Title'],
'publish_date': row['Publish Date'],
'kind': row['Type'],
'publish_year': row['Publish Year']
}
)
])
time.sleep(1) # Non-obligatory: Sleep to keep away from price limits
besides Exception as e:
print(f"Error processing article ID {row['ID']}: {e}")
print("All embeddings are saved within the vector database.")
You will note beneath in logs of created embeddings.
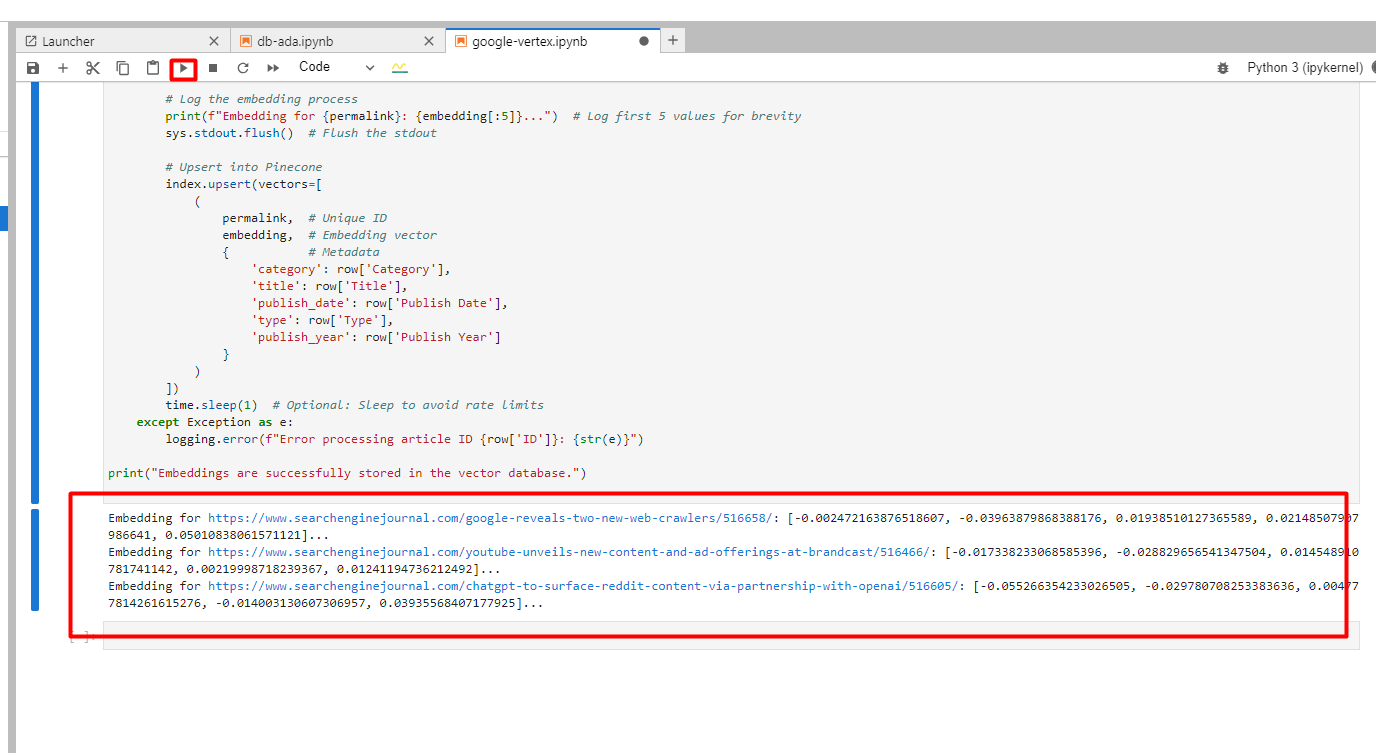 Screenshot from Google Cloud Console, December 2024
Screenshot from Google Cloud Console, December 20244. Discovering An Article Match For A Key phrase Utilizing Google Vertex AI
Now, let’s do the identical key phrase matching with Vertex AI. There’s a small nuance as it is advisable use ‘RETRIEVAL_QUERY’ vs. ‘RETRIEVAL_DOCUMENT’ as an argument when producing embeddings of key phrases as we try to carry out a seek for an article (aka doc) that greatest matches our phrase.
Activity sorts are one of many essential benefits that Vertex AI has over OpenAI’s fashions.
It ensures that the embeddings seize the intent of the key phrases which is essential for inner linking, and improves the relevance and accuracy of the matches present in your vector database.
Use this script for matching the key phrases to vectors.
import os
import pandas as pd
from google.cloud import aiplatform
from google.auth import load_credentials_from_file
from google.api_core.exceptions import ServiceUnavailable
from vertexai.language_models import TextEmbeddingModel
from pinecone import Pinecone
from tabulate import tabulate # For desk formatting
# Arrange your Google Cloud credentials
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "config.json" # Substitute along with your JSON key file
credentials, project_id = load_credentials_from_file(os.environ["GOOGLE_APPLICATION_CREDENTIALS"])
# Initialize Pinecone shopper
pinecone = Pinecone(api_key='YOUR_PINECON_API_KEY') # Add your Pinecone API key
index_name = "article-index-vertex" # Substitute along with your Pinecone index identify
index = pinecone.Index(index_name)
# Initialize Vertex AI
aiplatform.init(mission=project_id, credentials=credentials, location="us-central1")
def generate_embeddings(
textual content: str,
model_id: str = "text-embedding-005"
) -> checklist:
"""
Generates embeddings for the enter textual content utilizing Google Vertex AI's embedding mannequin.
Returns None if textual content is empty or an error happens.
"""
if not textual content or not textual content.strip():
print("Textual content enter is empty. Skipping.")
return None
attempt:
mannequin = TextEmbeddingModel.from_pretrained(model_id)
vector = mannequin.get_embeddings([text]) # Eliminated 'task_type' and 'output_dimensionality'
return vector[0].values
besides ServiceUnavailable as e:
print(f"Vertex AI service is unavailable: {e}")
return None
besides Exception as e:
print(f"Error producing embeddings: {e}")
return None
def match_keywords_to_index(key phrases):
"""
Matches a listing of keyword-category pairs to the closest articles within the Pinecone index,
filtering by metadata if specified.
"""
outcomes = []
for keyword_pair in key phrases:
key phrase = keyword_pair[0]
class = keyword_pair[1]
attempt:
keyword_vector = generate_embeddings(key phrase)
if not keyword_vector:
print(f"No embedding generated for key phrase '{key phrase}' in class '{class}'.")
outcomes.append({
'Key phrase': key phrase,
'Class': class,
'Match Rating': 'Error/Empty',
'Title': 'No match',
'URL': 'N/A'
})
proceed
query_results = index.question(
vector=keyword_vector,
top_k=1,
include_metadata=True,
filter={"class": class}
)
if query_results['matches']:
closest_match = query_results['matches'][0]
outcomes.append({
'Key phrase': key phrase,
'Class': class,
'Match Rating': f"{closest_match['score']:.2f}",
'Title': closest_match['metadata'].get('title', 'N/A'),
'URL': closest_match['id']
})
else:
outcomes.append({
'Key phrase': key phrase,
'Class': class,
'Match Rating': 'N/A',
'Title': 'No match discovered',
'URL': 'N/A'
})
besides Exception as e:
print(f"Error processing key phrase '{key phrase}' with class '{class}': {e}")
outcomes.append({
'Key phrase': key phrase,
'Class': class,
'Match Rating': 'Error',
'Title': 'Error occurred',
'URL': 'N/A'
})
return outcomes
# Instance utilization:
key phrases = [["SEO Tools", "Tools"], ["TikTok", "TikTok"], ["SEO Consultant", "SEO"]]
matches = match_keywords_to_index(key phrases)
# Show the ends in a desk
print(tabulate(matches, headers="keys", tablefmt="fancy_grid"))
And you will notice scores generated:
 Key phrase Matche Scores produced by Vertex AI textual content embedding mannequin
Key phrase Matche Scores produced by Vertex AI textual content embedding mannequinAttempt Testing The Relevance Of Your Article Writing
Consider this as a simplified (broad) approach to verify how semantically comparable your writing is to the pinnacle key phrase. Create a vector embedding of your head key phrase and whole article content material by way of Google’s Vertex AI and calculate a cosine similarity.
In case your textual content is just too lengthy it’s possible you’ll want to think about implementing chunking methods.
A detailed rating (cosine similarity) to 1.0 (like 0.8 or 0.7) means you’re fairly shut on that topic. In case your rating is decrease it’s possible you’ll discover that an excessively lengthy intro which has lots of fluff could also be inflicting dilution of the relevance and slicing it helps to extend it.
However keep in mind, any edits made ought to make sense from an editorial and consumer expertise perspective as properly.
You possibly can even do a fast comparability by embedding a competitor’s high-ranking content material and seeing the way you stack up.
Doing this lets you extra precisely align your content material with the goal topic, which can make it easier to rank higher.
There are already instruments that carry out such duties, however studying these abilities means you’ll be able to take a custom-made method tailor-made to your wants—and, after all, to do it without cost.
Experimenting for your self and studying these abilities will make it easier to to maintain forward with AI search engine optimization and to make knowledgeable selections.
As extra readings, I like to recommend you dive into these nice articles:
Extra sources:
Featured Picture: Aozorastock/Shutterstock