

{kind=link}
 Posted by Paul Ruiz � Senior Developer Relations Engineer, and Kris Tonthat � Technical Author
Posted by Paul Ruiz � Senior Developer Relations Engineer, and Kris Tonthat � Technical Author

Earlier this 12 months, we previewed on-device text-to-image technology with diffusion fashions for Android by way of MediaPipe Options. As we speak we�re glad to announce that that is accessible as an early, experimental resolution, Picture Generator, for builders to check out on Android gadgets, permitting you to simply generate pictures completely on-device in as shortly as ~15 seconds on increased finish gadgets. We will�t wait to see what you create!
There are three main ways in which you should utilize the brand new MediaPipe Picture Generator job:
- Textual content-to-image technology primarily based on textual content prompts utilizing customary diffusion fashions.
- Controllable text-to-image technology primarily based on textual content prompts and conditioning pictures utilizing diffusion plugins.
- Custom-made text-to-image technology primarily based on textual content prompts utilizing Low-Rank Adaptation (LoRA) weights that help you create pictures of particular ideas that you just pre-define on your distinctive use-cases.
Fashions
Earlier than we get into the entire enjoyable and thrilling components of this new MediaPipe job, it�s vital to know that our Picture Era API helps any fashions that precisely match the Secure Diffusion v1.5 structure. You should use a pretrained mannequin or your fine-tuned fashions by changing it to a mannequin format supported by MediaPipe Picture Generator utilizing our conversion script.
You may also customise a basis mannequin by way of MediaPipe Diffusion LoRA fine-tuning on Vertex AI, injecting new ideas right into a basis mannequin with out having to fine-tune the entire mannequin. You will discover extra details about this course of in our official documentation.
If you wish to do this job out right now with none customization, we additionally present hyperlinks to some verified working fashions in that very same documentation.
Picture Era via Diffusion Fashions
Essentially the most simple solution to strive the Picture Generator job is to provide it a textual content immediate, after which obtain a consequence picture utilizing a diffusion mannequin.
Like MediaPipe�s different duties, you’ll begin by creating an choices object. On this case you’ll solely have to outline the trail to your basis mannequin recordsdata on the system. After getting that choices object, you may create the ImageGenerator.
|
After creating your new ImageGenerator, you may create a brand new picture by passing within the immediate, the variety of iterations the generator ought to undergo for producing, and a seed worth. This may run a blocking operation to create a brand new picture, so it would be best to run it in a background thread earlier than returning your new Bitmap consequence object.
|
Along with this straightforward enter in/consequence out format, we additionally help a method so that you can step via every iteration manually via the execute() operate, receiving the intermediate consequence pictures again at completely different levels to point out the generative progress. Whereas getting intermediate outcomes again isn�t beneficial for many apps on account of efficiency and complexity, it’s a good solution to reveal what�s occurring below the hood. This is a bit more of an in-depth course of, however you could find this demo, in addition to the opposite examples proven on this submit, in our official instance app on GitHub.

Picture Era with Plugins
Whereas having the ability to create new pictures from solely a immediate on a tool is already a large step, we�ve taken it just a little additional by implementing a brand new plugin system which allows the diffusion mannequin to just accept a situation picture together with a textual content immediate as its inputs.
We at present help three other ways that you would be able to present a basis on your generations: facial constructions, edge detection, and depth consciousness. The plugins provide the capacity to offer a picture, extract particular constructions from it, after which create new pictures utilizing these constructions.

LoRA Weights
The third main function we�re rolling out right now is the power to customise the Picture Generator job with LoRA to show a basis mannequin a few new idea, corresponding to particular objects, folks, or types introduced throughout coaching. With the brand new LoRA weights, the Picture Generator turns into a specialised generator that is ready to inject particular ideas into generated pictures.
LoRA weights are helpful for circumstances the place you might have considered trying each picture to be within the fashion of an oil portray, or a selected teapot to seem in any created setting. You will discover extra details about LoRA weights on Vertex AI within the MediaPipe Secure Diffusion LoRA mannequin card, and create them utilizing this pocket book. As soon as generated, you may deploy the LoRA weights on-device utilizing the MediaPipe Duties Picture Generator API, or for optimized server inference via Vertex AI�s one-click deployment.
Within the instance beneath, we created LoRA weights utilizing a number of pictures of a teapot from the Dreambooth teapot coaching picture set. Then we use the weights to generate a brand new picture of the teapot in several settings.
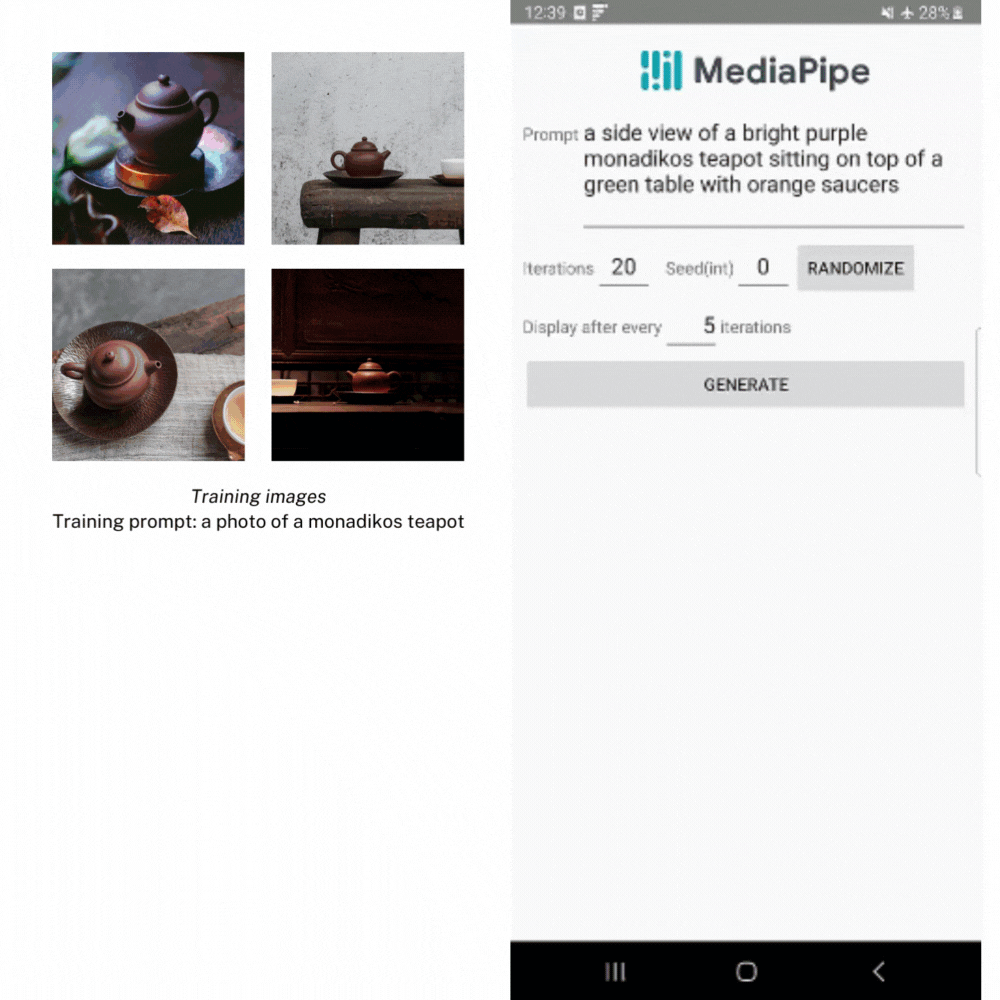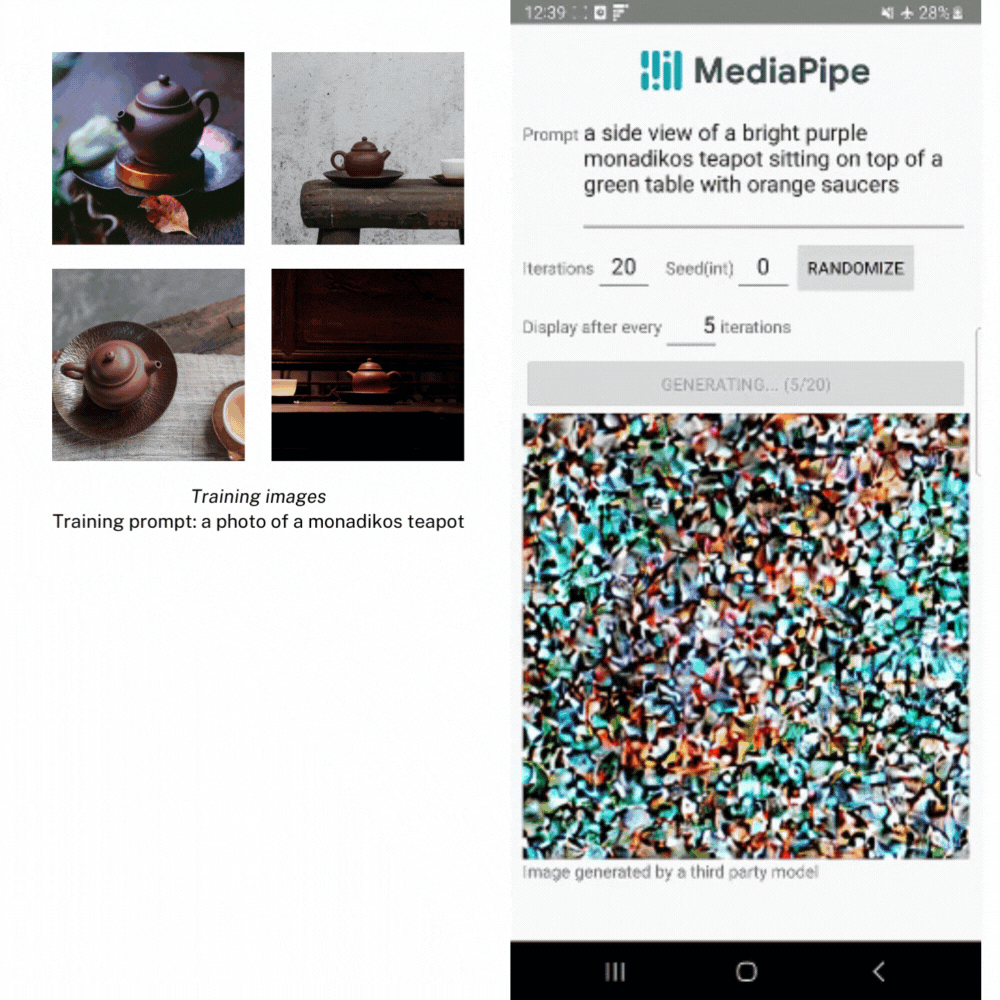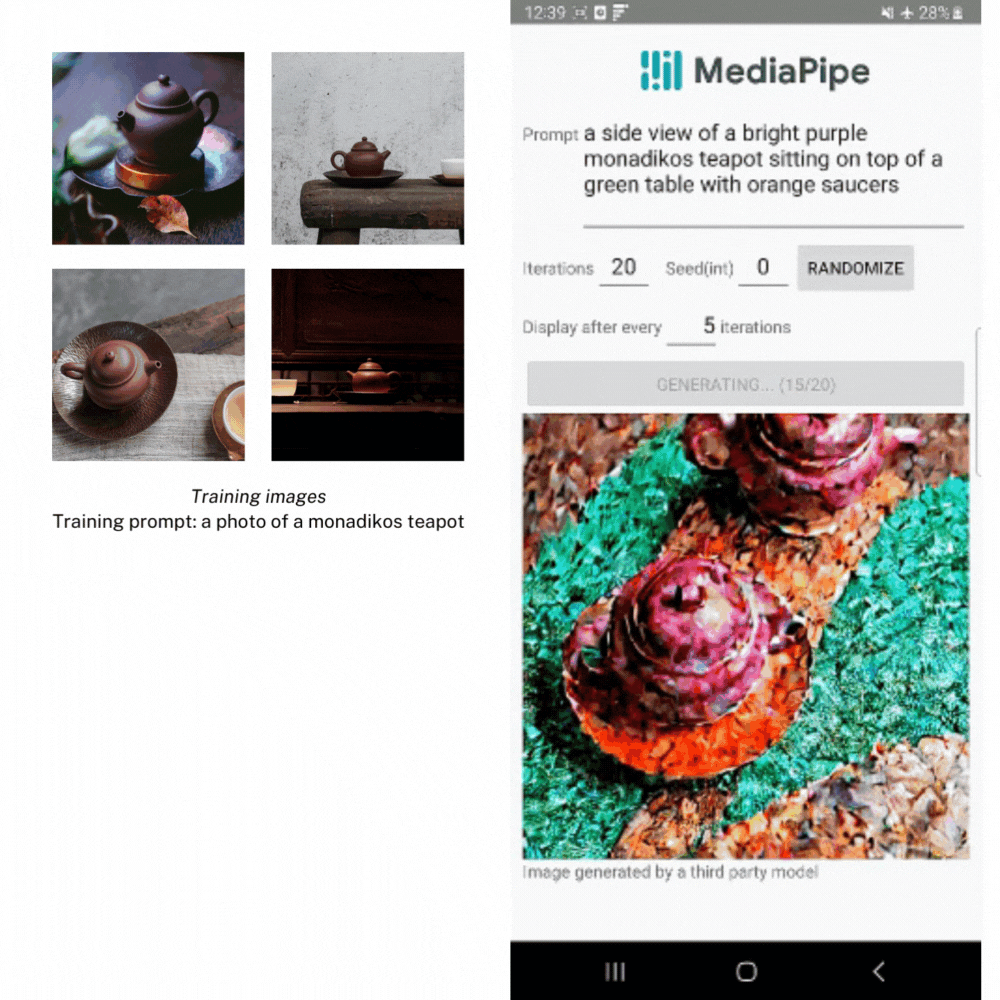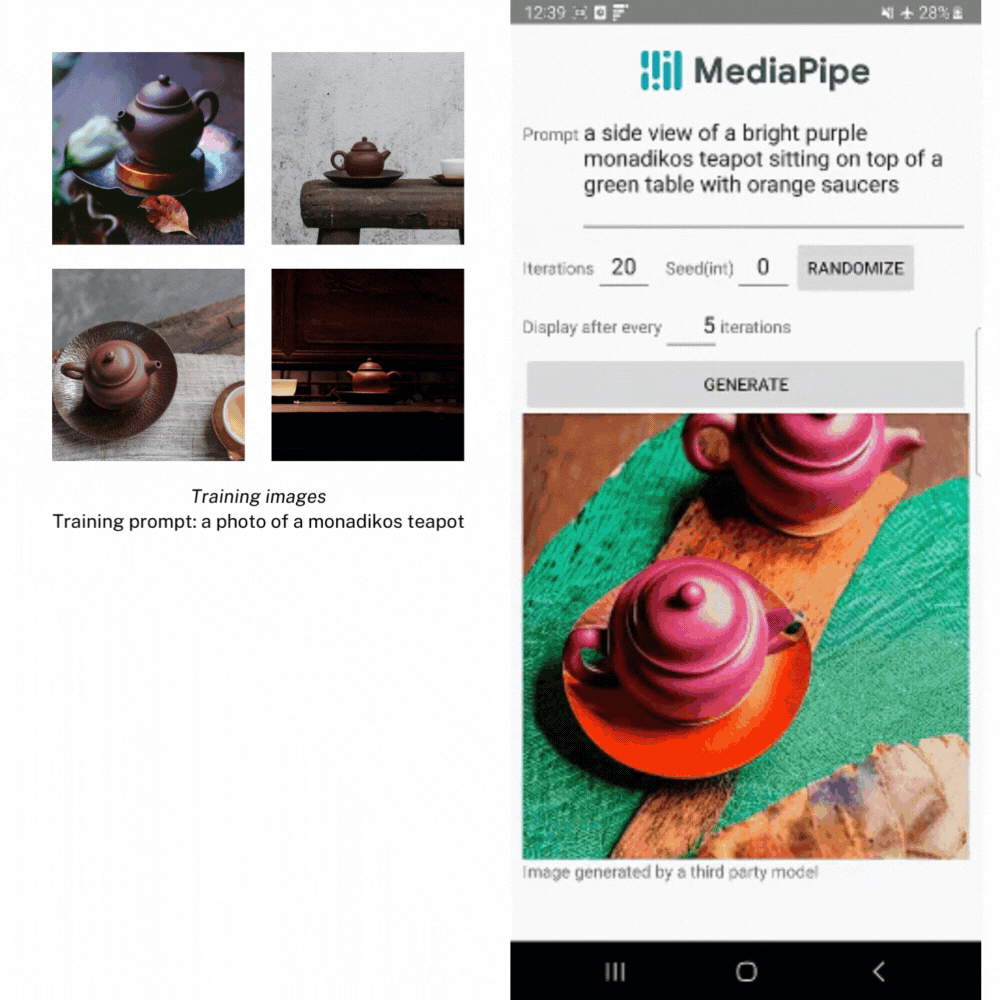
Subsequent Steps
That is just the start of what we plan to help with on-device picture technology. We�re trying ahead to seeing the entire nice issues the developer group builds, so remember to submit them on X (formally Twitter) with the hashtag #MediaPipeImageGen and tag @GoogleDevs. You may try the official pattern on GitHub demonstrating all the pieces you�ve simply realized about, learn via our official documentation for much more particulars, and keep watch over the Google for Builders YouTube channel for updates and tutorials as they�re launched by the MediaPipe staff.
Acknowledgements
We�d wish to thank all staff members who contributed to this work: Lu Wang, Yi-Chun Kuo, Sebastian Schmidt, Kris Tonthat, Jiuqiang Tang, Khanh LeViet, Paul Ruiz, Qifei Wang, Yang Zhao, Yuqi Li, Lawrence Chan, Tingbo Hou, Joe Zou, Raman Sarokin, Juhyun Lee, Geng Yan, Ekaterina Ignasheva, Shanthal Vasanth, Glenn Cameron, Mark Sherwood, Andrei Kulik, Chuo-Ling Chang, and Matthias Grundmann from the Core ML staff, in addition to Changyu Zhu, Genquan Duan, Bo Wu, Ting Yu, and Shengyang Dai from Google Cloud.