
{kind=link}
A information lake is a centralized repository that you need to use to retailer all of your structured and unstructured information at any scale. You possibly can retailer your information as-is, with out having to first construction the information after which run several types of analytics for higher enterprise insights. Over time, information lakes on Amazon Easy Storage Service (Amazon S3) have turn out to be the default repository for enterprise information and are a typical alternative for a big set of customers who question information for quite a lot of analytics and machine leaning use instances. Amazon S3 means that you can entry various information units, construct enterprise intelligence dashboards, and speed up the consumption of information by adopting a trendy information structure or information mesh sample on Amazon Net Companies (AWS).
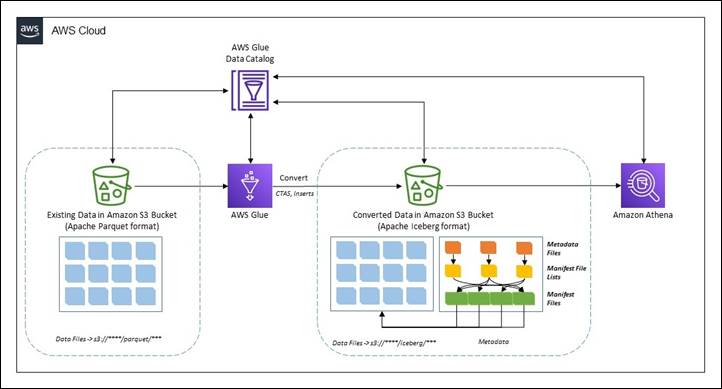
Analytics use instances on information lakes are all the time evolving. Oftentimes, you wish to repeatedly ingest information from numerous sources into a knowledge lake and question the information concurrently by a number of analytics instruments with transactional capabilities. However historically, information lakes constructed on Amazon S3 are immutable and don�t present the transactional capabilities wanted to assist altering use instances. With altering use instances, clients are searching for methods to not solely transfer new or incremental information to information lakes as transactions, but additionally to transform present information based mostly on Apache Parquet to a transactional format. Open desk codecs, corresponding to Apache Iceberg, present an answer to this difficulty. Apache Iceberg permits transactions on information lakes and might simplify information storage, administration, ingestion, and processing.
On this submit, we present you how one can convert present information in an Amazon S3 information lake in Apache Parquet format to Apache Iceberg format to assist transactions on the information utilizing Jupyter Pocket book based mostly interactive classes over AWS Glue 4.0.
Present Parquet to Iceberg migration
There are two broad strategies emigrate the present information in a knowledge lake in Apache Parquet format to Apache Iceberg format to transform the information lake to a transactional desk format.
In-place information improve
In an in-place information migration technique, present datasets are upgraded to Apache Iceberg format with out first reprocessing or restating present information. This implies the information information within the information lake aren�t modified throughout the migration and all Apache Iceberg metadata information (manifests, manifest information, and desk metadata information) are generated exterior the purview of the information. On this methodology, the metadata are recreated in an remoted atmosphere and colocated with the present information information. This is usually a a lot cheaper operation in comparison with rewriting all the information information. The prevailing information file format have to be Apache Parquet, Apache ORC, or Apache Avro. An in-place migration could be carried out in both of two methods:
- Utilizing add_files: This process provides present information information to an present Iceberg desk with a brand new snapshot that features the information. In contrast to migrate or snapshot,
add_filescan import information from a selected partition or partitions and doesn�t create a brand new Iceberg desk. This process doesn�t analyze the schema of the information to find out in the event that they match the schema of the Iceberg desk. Upon completion, the Iceberg desk treats these information as if they’re a part of the set of information owned by Apache Iceberg. - Utilizing migrate: This process replaces a desk with an Apache Iceberg desk loaded with the supply�s information information. The desk�s schema, partitioning, properties, and placement are copied from the supply desk. Supported codecs are Avro, Parquet, and ORC. By default, the unique desk is retained with the identify
table_BACKUP_. Nonetheless, to depart the unique desk intact throughout the course of, you should use snapshot to create a brand new non permanent desk that has the identical supply information information and schema.
On this submit, we present you ways you need to use the Iceberg add_files process for an in-place information improve. Observe that the migrate process isn�t supported in AWS Glue Information Catalog.
The next diagram exhibits a high-level illustration.

CTAS migration of information
The create desk as choose (CTAS) migration strategy is a way the place all of the metadata data for Iceberg is generated together with restating all the information information. This methodology shadows the supply dataset in batches. When the shadow is caught up, you may swap the shadowed dataset with the supply.
The next diagram showcases the high-level movement.
Stipulations
To observe together with the walkthrough, you should have the next:
You possibly can examine the information dimension utilizing the next code within the AWS CLI or AWS CloudShell:
As of scripting this submit, there are 107 objects with whole dimension of 70 MB for yr 2023 within the Amazon S3 path.

Observe that to implement the answer, you should full a couple of preparatory steps.
Deploy assets utilizing AWS CloudFormation
Full the next steps to create the S3 bucket and the AWS IAM position and coverage for the answer:
- Register to your AWS account after which select Launch Stack to launch the CloudFormation template.
![]()
- For Stack identify, enter a reputation.
- Depart the parameters on the default values. Observe that if the default values are modified, then you should make corresponding modifications all through the next steps.
- Select Subsequent to create your stack.
This AWS CloudFormation template deploys the next assets:
- An S3 bucket named
demo-blog-post-XXXXXXXX(XXXXXXXXrepresents the AWS account ID used). - Two folders named
parquetandicebergbeneath the bucket. - An IAM position and a coverage named
demoblogpostroleanddemoblogpostscopedrespectively. - An AWS Glue database named
ghcn_db. - An AWS Glue Crawler named
demopostcrawlerparquet.

After the the AWS CloudFormation template is efficiently deployed:
- Copy the information within the created S3 bucket utilizing following command in AWS CLI or AWS CloudShell. Exchange
XXXXXXXXappropriately within the goal S3 bucket identify.
Observe: Within the instance, we copy information just for the yr 2023. Nonetheless, you may work with all the dataset, following the identical directions. - Open the AWS Administration Console and go to the AWS Glue console.
- On the navigation pane, choose Crawlers.
- Run the crawler named
demopostcrawlerparquet. - After the AWS Glue crawler
demopostcrawlerparquetis efficiently run, the metadata data of the Apache Parquet information might be cataloged beneath theghcn_dbAWS Glue database with the desk identifysource_parquet. Discover that the desk is partitioned overyrandaspectcolumns (as within the S3 bucket).

- Use the next question to confirm the information from the Amazon Athena console. When you�re utilizing Amazon Athena for the primary time in your AWS Account, arrange a question consequence location in Amazon S3.

Launch an AWS Glue Studio pocket book for processing
For this submit, we use an AWS Glue Studio pocket book. Comply with the steps in Getting began with notebooks in AWS Glue Studio to arrange the pocket book atmosphere. Launch the notebooks hosted beneath this hyperlink and unzip them on an area workstation.
- Open AWS Glue Studio.
- Select ETL Jobs.
- Select Jupyter pocket book after which select Add and edit an present pocket book. From Select file, choose required
ipynbfile and select Open, then select Create. - On the Pocket book setup web page, for Job identify, enter a logical identify.
- For IAM position, choose
demoblogpostrole. Select Create job. After a minute, the Jupyter pocket book editor seems. Clear all of the default cells.
The previous steps launch an AWS Glue Studio pocket book atmosphere. Be sure to Save the pocket book each time it�s used.
In-place information improve
On this part we present you ways you need to use the add_files process to attain an in-place information improve. This part makes use of the ipynb file named demo-in-place-upgrade-addfiles.ipynb. To make use of with the add_files process, full the next:
- On the Pocket book setup web page, for Job identify, enter
demo-in-place-upgradefor the pocket book session as defined in Launch Glue pocket book for processing. - Run the cells beneath the part Glue session configurations. Present the S3 bucket identify from the stipulations for the
bucket_namevariable by changingXXXXXXXX. - Run the following cells within the pocket book.
Discover that the cell beneath Execute add_files process part performs the metadata creation within the talked about path.

Evaluation the information file paths for the brand new Iceberg desk. To point out an Iceberg desk�s present information information, .information can be utilized to get particulars corresponding to file_path, partition, and others. Recreated information are pointing to the supply path beneath Amazon S3.

Observe the metadata file location after transformation. It�s pointing to the brand new folder named iceberg beneath Amazon S3. This may be checked utilizing .snapshots to examine Iceberg tables� snapshot file location. Additionally, examine the identical within the Amazon S3 URI s3://demo-blog-post-XXXXXXXX/iceberg/ghcn_db.db/target_iceberg_add_files/metadata/. Additionally discover that there are two variations of the manifest listing created after the add_files process has been run. The primary is an empty desk with the information schema and the second is including the information.


The desk is cataloged in AWS Glue beneath the database ghcn_db with the desk sort as ICEBERG.

Examine the depend of information utilizing Amazon Athena between the supply and goal desk. They’re the identical.

In abstract, you need to use the add_files process to transform present information information in Apache Parquet format in a knowledge lake to Apache Iceberg format by including the metadata information and with out recreating the desk from scratch. Following are some professionals and cons of this methodology.
Professionals
- Avoids full desk scans to learn the information as there is no such thing as a restatement. This could save time.
- If there are any errors throughout whereas writing the metadata, solely a metadata re-write is required and never all the information.
- Lineage of the present jobs is maintained as a result of the present catalog nonetheless exists.
Cons
- If information is processed (inserts, updates, and deletes) within the dataset throughout the metadata writing course of, the method have to be run once more to incorporate the brand new information.
- There have to be write downtime to keep away from having to run the method a second time.
- If a knowledge restatement is required, this workflow is not going to work as supply information information aren�t modified.
CTAS migration of information
This part makes use of the ipynb file named demo-ctas-upgrade.ipynb. Full the next:
- On the Pocket book setup web page, for Job identify, enter
demo-ctas-upgradefor the pocket book session as defined beneath Launch Glue pocket book for processing. - Run the cells beneath the part Glue session configurations. Present the S3 bucket identify from the stipulations for the
bucket_namevariable by changingXXXXXXXX. - Run the following cells within the pocket book.
Discover that the cell beneath Create Iceberg desk from Parquet part performs the shadow improve to Iceberg format. Observe that Iceberg requires sorting the information in accordance with desk partitions earlier than writing to the Iceberg desk. Additional particulars could be present in Writing Distribution Modes.

Discover the information and metadata file paths for the brand new Iceberg desk. It�s pointing to the brand new path beneath Amazon S3. Additionally, examine beneath the Amazon S3 URI s3://demo-blog-post-XXXXXXXX/iceberg/ghcn_db.db/target_iceberg_ctas/ used for this submit.


The desk is cataloged beneath AWS Glue beneath the database ghcn_db with the desk sort as ICEBERG.

Examine the depend of information utilizing Amazon Athena between the supply and goal desk. They’re identical.

In abstract, the CTAS methodology creates a brand new desk by producing all of the metadata information together with restating the precise information. Following are some professionals and cons of this methodology:
Professionals
- It means that you can audit and validate the information throughout the course of as a result of information is restated.
- If there are any runtime points throughout the migration course of, rollback and restoration could be simply carried out by deleting the Apache Iceberg desk.
- You possibly can take a look at completely different configurations when migrating a supply. You possibly can create a brand new desk for every configuration and consider the impression.
- Shadow information is renamed to a distinct listing within the supply (so it doesn�t collide with previous Apache Parquet information).
Cons
- Storage of the dataset is doubled throughout the course of as each the unique Apache Parquet and new Apache Iceberg tables are current throughout the migration and testing part. This must be thought-about throughout price estimation.
- The migration can take for much longer (relying on the amount of the information) as a result of each information and metadata are written.
- It�s tough to maintain tables in sync if there modifications to the supply desk throughout the course of.
Clear up
To keep away from incurring future fees, and to scrub up unused roles and insurance policies, delete the assets you created: the datasets, CloudFormation stack, S3 bucket, AWS Glue job, AWS Glue database, and AWS Glue desk.
Conclusion
On this submit, you realized methods for migrating present Apache Parquet formatted information to Apache Iceberg in Amazon S3 to transform to a transactional information lake utilizing interactive classes in AWS Glue 4.0 to finish the processes. You probably have an evolving use case the place an present information lake must be transformed to a transactional information lake based mostly on Apache Iceberg desk format, observe the steerage on this submit.
The trail you select for this improve, an in-place improve or CTAS migration, or a mixture of each, will rely on cautious evaluation of the information structure and information integration pipeline. Each pathways have professionals and cons, as mentioned. At a excessive stage, this improve course of ought to undergo a number of well-defined phases to establish the patterns of information integration and use instances. Selecting the right technique will rely in your necessities�corresponding to efficiency, price, information freshness, acceptable downtime throughout migration, and so forth.
Concerning the writer
 Rajdip Chaudhuri is a Senior Options Architect with Amazon Net Companies specializing in information and analytics. He enjoys working with AWS clients and companions on information and analytics necessities. In his spare time, he enjoys soccer and films.
Rajdip Chaudhuri is a Senior Options Architect with Amazon Net Companies specializing in information and analytics. He enjoys working with AWS clients and companions on information and analytics necessities. In his spare time, he enjoys soccer and films.