

{kind=link}
Organizations with legacy, on-premises, near-real-time analytics options usually depend on self-managed relational databases as their knowledge retailer for analytics workloads. To reap the advantages of cloud computing, like elevated agility and just-in-time provisioning of assets, organizations are migrating their legacy analytics functions to AWS. The raise and shift migration method is proscribed in its means to rework companies as a result of it depends on outdated, legacy applied sciences and architectures that restrict flexibility and decelerate productiveness. On this put up, we talk about methods to modernize your legacy, on-premises, real-time analytics structure to construct serverless knowledge analytics options on AWS utilizing Amazon Managed Service for Apache Flink.
Close to-real-time streaming analytics captures the worth of operational knowledge and metrics to supply new insights to create enterprise alternatives. On this put up, we talk about challenges with relational databases when used for real-time analytics and methods to mitigate them by modernizing the structure with serverless AWS options. We introduce you to Amazon Managed Service for Apache Flink Studio and get began querying streaming knowledge interactively utilizing Amazon Kinesis Knowledge Streams.
Resolution overview
On this put up, we stroll by means of a name heart analytics resolution that gives insights into the decision heart�s efficiency in near-real time by means of metrics that decide agent effectivity in dealing with calls within the queue. Key efficiency indicators (KPIs) of curiosity for a name heart from a near-real-time platform might be calls ready within the queue, highlighted in a efficiency dashboard inside a couple of seconds of information ingestion from name heart streams. These metrics assist brokers enhance their name deal with time and likewise reallocate brokers throughout organizations to deal with pending calls within the queue.
Historically, such a legacy name heart analytics platform could be constructed on a relational database that shops knowledge from streaming sources. Knowledge transformations by means of saved procedures and use of materialized views to curate datasets and generate insights is a identified sample with relational databases. Nonetheless, as knowledge loses its relevance with time, transformations in a near-real-time analytics platform want solely the newest knowledge from the streams to generate insights. This may occasionally require frequent truncation in sure tables to retain solely the newest stream of occasions. Additionally, the necessity to derive near-real-time insights inside seconds requires frequent materialized view refreshes on this conventional relational database method. Frequent materialized view refreshes on prime of continually altering base tables on account of streamed knowledge can result in snapshot isolation errors. Additionally, an information mannequin that enables desk truncations at a daily frequency (for instance, each 15 seconds) to retailer solely related knowledge in tables may cause locking and efficiency points.
The next diagram gives the high-level structure of a legacy name heart analytics platform. On this conventional structure, a relational database is used to retailer knowledge from streaming knowledge sources. Datasets used for producing insights are curated utilizing materialized views contained in the database and printed for enterprise intelligence (BI) reporting.

Modernizing this conventional database-driven structure within the AWS Cloud permits you to use subtle streaming applied sciences like Amazon Managed Service for Apache Flink, that are constructed to rework and analyze streaming knowledge in actual time. With Amazon Managed Service for Apache Flink, you possibly can achieve actionable insights from streaming knowledge with serverless, totally managed Apache Flink. You should utilize Amazon Managed Service for Apache Flink to rapidly construct end-to-end stream processing functions and course of knowledge repeatedly, getting insights in seconds or minutes. With Amazon Managed Service for Apache Flink, you should utilize Apache Flink code or Flink SQL to repeatedly generate time-series analytics over time home windows and carry out subtle joins throughout streams.
The next structure diagram illustrates how a legacy name heart analytics platform working on databases will be modernized to run on the AWS Cloud utilizing Amazon Managed Service for Apache Flink. It exhibits a name heart streaming knowledge supply that sends the newest name heart feed in each 15 seconds. The second streaming knowledge supply constitutes metadata details about the decision heart group and brokers that will get refreshed all through the day. You’ll be able to carry out subtle joins over these streaming datasets and create views on prime of it utilizing Amazon Managed Service for Apache Flink to generate KPIs required for the enterprise utilizing Amazon OpenSearch Service. You’ll be able to analyze streaming knowledge interactively utilizing managed Apache Zeppelin notebooks with Amazon Managed Service for Apache Flink Studio in near-real time. The near-real-time insights can then be visualized as a efficiency dashboard utilizing OpenSearch Dashboards.

On this put up, you carry out the next high-level implementation steps:
- Ingest knowledge from streaming knowledge sources to Kinesis Knowledge Streams.
- Use managed Apache Zeppelin notebooks with Amazon Managed Service for Apache Flink Studio to rework the stream knowledge inside seconds of information ingestion.
- Visualize KPIs of name heart efficiency in near-real time by means of OpenSearch Dashboards.
Stipulations
This put up requires you to arrange the Amazon Kinesis Knowledge Generator (KDG) to ship knowledge to a Kinesis knowledge stream utilizing an AWS CloudFormation template. For the template and setup data, discuss with Check Your Streaming Knowledge Resolution with the New Amazon Kinesis Knowledge Generator.
We use two datasets on this put up. The primary dataset is truth knowledge, which incorporates name heart group knowledge. The KDG generates a truth knowledge feed in each 15 seconds that incorporates the next data:
- AgentId � Brokers work in a name heart setting surrounded by different name heart staff answering prospects� questions and referring them to the required assets to unravel their issues.
- OrgId � A name heart incorporates completely different organizations and departments, comparable to Care Hub, IT Hub, Allied Hub, Prem Hub, Assist Hub, and extra.
- QueueId � Name queues present an efficient method to route calls utilizing easy or subtle patterns to make sure that all calls are entering into the right arms rapidly.
- WorkMode � An agent work mode determines your present state and availability to obtain incoming calls from the Computerized Name Distribution (ACD) and Direct Agent Name (DAC) queues. Name Middle Elite doesn’t route ACD and DAC calls to your cellphone if you end up in an Aux mode or ACW mode.
- WorkSkill � Working as a name heart agent requires a number of delicate abilities to see one of the best outcomes, like problem-solving, bilingualism, channel expertise, aptitude with knowledge, and extra.
- HandleTime � This customer support metric measures the size of a buyer�s name.
- ServiceLevel � The decision heart service stage is outlined as the share of calls answered inside a predefined period of time�the goal time threshold. It may be measured over any time period (comparable to half-hour, 1 hour, 1 day, or 1 week) and for every agent, workforce, division, or the corporate as a complete.
- WorkStates � This specifies what state an agent is in. For instance, an agent in an out there state is accessible to deal with calls from an ACD queue. An agent can have a number of states with respect to completely different ACD units, or they will use a single state to explain their relationship to all ACD units. Agent states are reported in agent-state occasions.
- WaitingTime � That is the typical time an inbound name spends ready within the queue or ready for a callback if that characteristic is lively in your IVR system.
- EventTime � That is the time when the decision heart stream is shipped (by way of the KDG on this put up).
The next truth payload is used within the KDG to generate pattern truth knowledge:
The next screenshot exhibits the output of the pattern truth knowledge in an Amazon Managed Service for Apache Flink pocket book.

The second dataset is dimension knowledge. This knowledge incorporates metadata data like group names for his or her respective group IDs, agent names, and extra. The frequency of the dimension dataset is twice a day, whereas the actual fact dataset will get loaded in each 15 seconds. On this put up, we use Amazon Easy Storage Service (Amazon S3) as an information storage layer to retailer metadata data (Amazon DynamoDB can be utilized to retailer metadata data as properly). We use AWS Lambda to load metadata from Amazon S3 to a different Kinesis knowledge stream that shops metadata data. The next JSON file saved in Amazon S3 has metadata mappings to be loaded into the Kinesis knowledge stream:
Ingest knowledge from streaming knowledge sources to Kinesis Knowledge Streams
To begin ingesting your knowledge, full the next steps:
- Create two Kinesis knowledge streams for the actual fact and dimension datasets, as proven within the following screenshot. For directions, discuss with Making a Stream by way of the AWS Administration Console.

- Create a Lambda operate on the Lambda console to load metadata information from Amazon S3 to Kinesis Knowledge Streams. Use the next code:
Use managed Apache Zeppelin notebooks with Amazon Managed Service for Apache Flink Studio to rework the streaming knowledge
The following step is to create tables in Amazon Managed Service for Apache Flink Studio for additional transformations (joins, aggregations, and so forth). To arrange and question Kinesis Knowledge Streams utilizing Amazon Managed Service for Apache Flink Studio, discuss with Question your knowledge streams interactively utilizing Amazon Managed Service for Apache Flink Studio and Python and create an Amazon Managed Service for Apache Flink pocket book. Then full the next steps:
- Within the Amazon Managed Service for Apache Flink Studio pocket book, create a truth desk from the information knowledge stream you created earlier, utilizing the next question.
The occasion time attribute is outlined utilizing a WATERMARK assertion within the CREATE desk DDL. A WATERMARK assertion defines a watermark era expression on an present occasion time area, which marks the occasion time area because the occasion time attribute.
The occasion time refers back to the processing of streaming knowledge based mostly on timestamps which might be hooked up to every row. The timestamps can encode when an occasion occurred. Processing time (PROCTime) refers back to the machine�s system time that’s working the respective operation.

- Create a dimension desk within the Amazon Managed Service for Apache Flink Studio pocket book that makes use of the metadata Kinesis knowledge stream:

- Create a versioned view to extract the newest model of metadata desk values to be joined with the information desk:

- Be a part of the information and versioned metadata desk on
orgIDand create a view that gives the whole calls within the queue in every group in a span of each 5 seconds, for additional reporting. Moreover, create a tumble window of 5 seconds to obtain the ultimate output in each 5 seconds. See the next code:

- Now you possibly can run the next question from the view you created and see the leads to the pocket book:

Visualize KPIs of name heart efficiency in near-real time by means of OpenSearch Dashboards
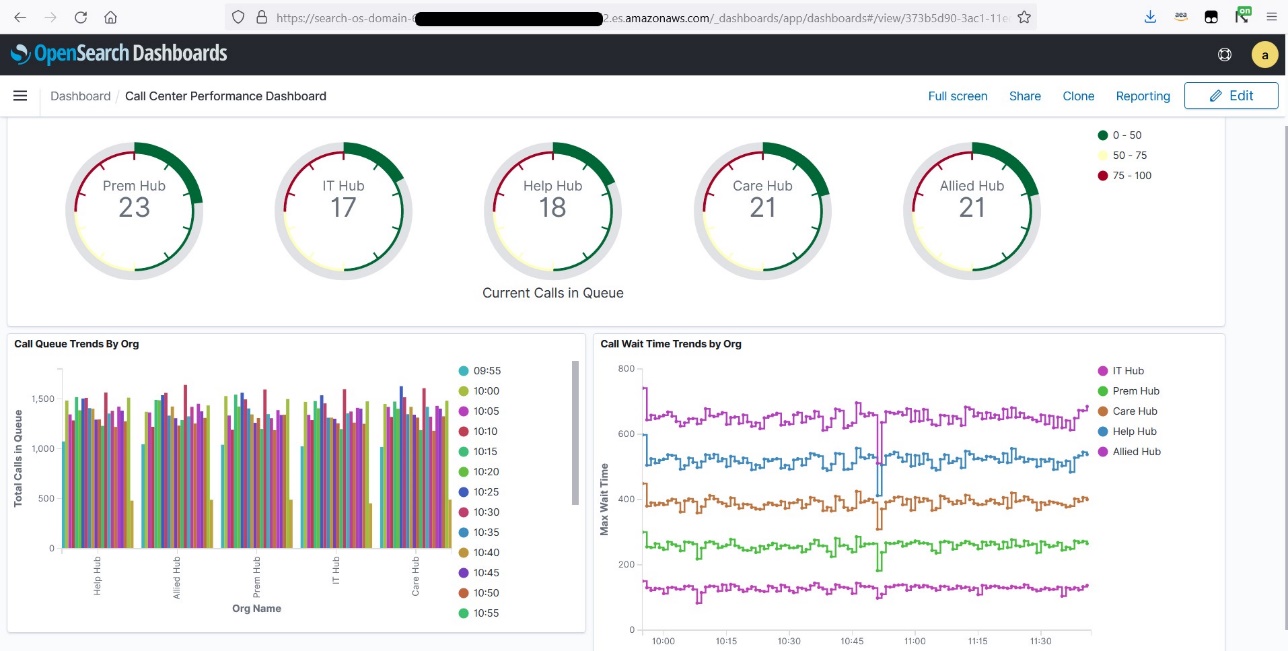
You’ll be able to publish the metrics generated inside Amazon Managed Service for Apache Flink Studio to OpenSearch Service and visualize metrics in near-real time by making a name heart efficiency dashboard, as proven within the following instance. Consult with Stream the information and validate output to configure OpenSearch Dashboards with Amazon Managed Service for Apache Flink. After you configure the connector, you possibly can run the next command from the pocket book to create an index in an OpenSearch Service cluster.
The active_call_queue index is created in OpenSearch Service. The next screenshot exhibits an index sample from OpenSearch Dashboards.

Now you possibly can create visualizations in OpenSearch Dashboards. The next screenshot exhibits an instance.
Conclusion
On this put up, we mentioned methods to modernize a legacy, on-premises, real-time analytics structure and construct a serverless knowledge analytics resolution on AWS utilizing Amazon Managed Service for Apache Flink. We additionally mentioned challenges with relational databases when used for real-time analytics and methods to mitigate them by modernizing the structure with serverless AWS options.
When you’ve got any questions or solutions, please go away us a remark.
Concerning the Authors
 Bhupesh Sharma is a Senior Knowledge Engineer with AWS. His function helps prospects architect highly-available, high-performance, and cost-effective knowledge analytics options to empower prospects with data-driven decision-making. In his free time, he enjoys enjoying musical devices, street biking, and swimming.
Bhupesh Sharma is a Senior Knowledge Engineer with AWS. His function helps prospects architect highly-available, high-performance, and cost-effective knowledge analytics options to empower prospects with data-driven decision-making. In his free time, he enjoys enjoying musical devices, street biking, and swimming.
 Devika Singh is a Senior Knowledge Engineer at Amazon, with deep understanding of AWS companies, structure, and cloud-based finest practices. Along with her experience in knowledge analytics and AWS cloud migrations, she gives technical steering to the group, on architecting and constructing an economical, safe and scalable resolution, that’s pushed by enterprise wants. Past her skilled pursuits, she is keen about classical music and journey.
Devika Singh is a Senior Knowledge Engineer at Amazon, with deep understanding of AWS companies, structure, and cloud-based finest practices. Along with her experience in knowledge analytics and AWS cloud migrations, she gives technical steering to the group, on architecting and constructing an economical, safe and scalable resolution, that’s pushed by enterprise wants. Past her skilled pursuits, she is keen about classical music and journey.