

{kind=link}

|
In July, we introduced the preview of brokers for Amazon Bedrock, a brand new functionality for builders to create generative AI functions that full duties. Right now, I�m comfortable to introduce a brand new functionality to securely join basis fashions (FMs) to your organization knowledge sources utilizing brokers.
With a data base, you need to use brokers to provide FMs in Bedrock entry to further knowledge that helps the mannequin generate extra related, context-specific, and correct responses with out constantly retraining the FM. Primarily based on person enter, brokers determine the suitable data base, retrieve the related data, and add the knowledge to the enter immediate, giving the mannequin extra context data to generate a completion.
Brokers for Amazon Bedrock use an idea often known as retrieval augmented era (RAG) to realize this. To create a data base, specify the Amazon Easy Storage Service (Amazon S3) location of your knowledge, choose an embedding mannequin, and supply the main points of your vector database. Bedrock converts your knowledge into embeddings and shops your embeddings within the vector database. Then, you’ll be able to add the data base to brokers to allow RAG workflows.
For the vector database, you’ll be able to select between vector engine for Amazon OpenSearch Serverless, Pinecone, and Redis Enterprise Cloud. I�ll share extra particulars on tips on how to arrange your vector database later on this publish.
Primer on Retrieval Augmented Technology, Embeddings, and Vector Databases
RAG isn�t a selected set of applied sciences however an idea for offering FMs entry to knowledge they didn�t see throughout coaching. Utilizing RAG, you’ll be able to increase FMs with further data, together with company-specific knowledge, with out constantly retraining your mannequin.
Repeatedly retraining your mannequin shouldn’t be solely compute-intensive and costly, however as quickly as you�ve retrained the mannequin, your organization might need already generated new knowledge, and your mannequin has stale data. RAG addresses this problem by offering your mannequin entry to further exterior knowledge at runtime. Related knowledge is then added to the immediate to assist enhance each the relevance and the accuracy of completions.
This knowledge can come from a lot of knowledge sources, resembling doc shops or databases. A standard implementation for doc search is changing your paperwork, or chunks of the paperwork, into vector embeddings utilizing an embedding mannequin after which storing the vector embeddings in a vector database, as proven within the following determine.
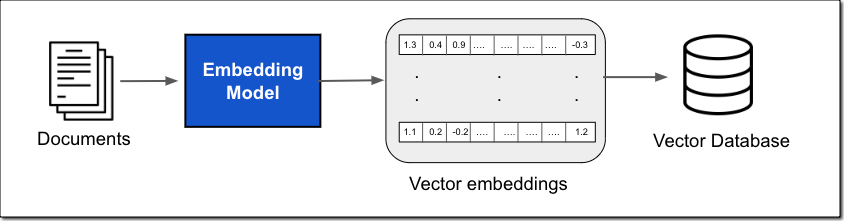
The vector embedding consists of the numeric representations of textual content knowledge inside your paperwork. Every embedding goals to seize the semantic or contextual which means of the info. Every vector embedding is put right into a vector database, typically with further metadata resembling a reference to the unique content material the embedding was created from. The vector database then indexes the vectors, which might be performed utilizing a wide range of approaches. This indexing permits fast retrieval of related knowledge.
In comparison with conventional key phrase search, vector search can discover related outcomes with out requiring an actual key phrase match. For instance, for those who seek for �What’s the price of product X?� and your paperwork say �The worth of product X is [�]�, then key phrase search won’t work as a result of �worth� and �price� are two totally different phrases. With vector search, it is going to return the correct consequence as a result of �worth� and �price� are semantically related; they’ve the identical which means. Vector similarity is calculated utilizing distance metrics resembling Euclidean distance, cosine similarity, or dot product similarity.
The vector database is then used inside the immediate workflow to effectively retrieve exterior data primarily based on an enter question, as proven within the determine beneath.

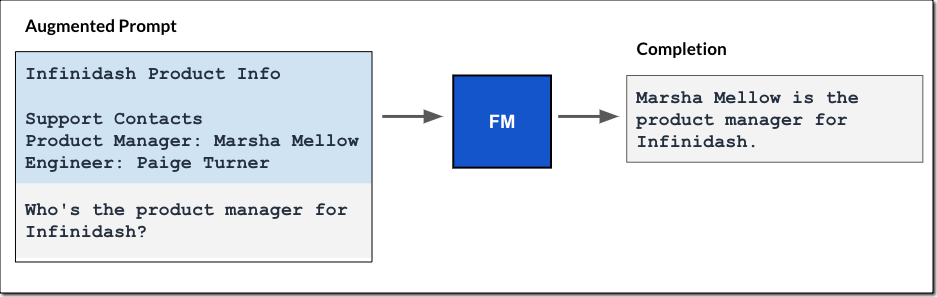
The workflow begins with a person enter immediate. Utilizing the identical embedding mannequin, you create a vector embedding illustration of the enter immediate. This embedding is then used to question the database for related vector embeddings to return probably the most related textual content because the question consequence.
The question result’s then added to the immediate, and the augmented immediate is handed to the FM. The mannequin makes use of the extra context within the immediate to generate the completion, as proven within the following determine.
Just like the totally managed brokers expertise I described within the weblog publish on brokers for Amazon Bedrock, the data base for Amazon Bedrock manages the info ingestion workflow, and brokers handle the RAG workflow for you.
Get Began with Data Bases for Amazon Bedrock
You may add a data base by specifying a knowledge supply, resembling Amazon S3, choose an embedding mannequin, resembling Amazon Titan Embeddings to transform the info into vector embeddings, and a vacation spot vector database to retailer the vector knowledge. Bedrock takes care of making, storing, managing, and updating your embeddings within the vector database.
Should you add data bases to an agent, the agent will determine the suitable data base primarily based on person enter, retrieve the related data, and add the knowledge to the enter immediate, offering the mannequin with extra context data to generate a response, as proven within the determine beneath. All data retrieved from data bases comes with supply attribution to enhance transparency and decrease hallucinations.

Let me stroll you thru these steps in additional element.
Create a Data Base for Amazon Bedrock
Let�s assume you�re a developer at a tax consulting firm and need to present customers with a generative AI utility�a TaxBot�that may reply US tax submitting questions.�You first create a data base that holds the related tax paperwork. Then, you configure an agent in Bedrock with entry to this information base and combine the agent into your TaxBot utility.
To get began, open the Bedrock console, choose Data base within the left navigation pane, then select Create data base.
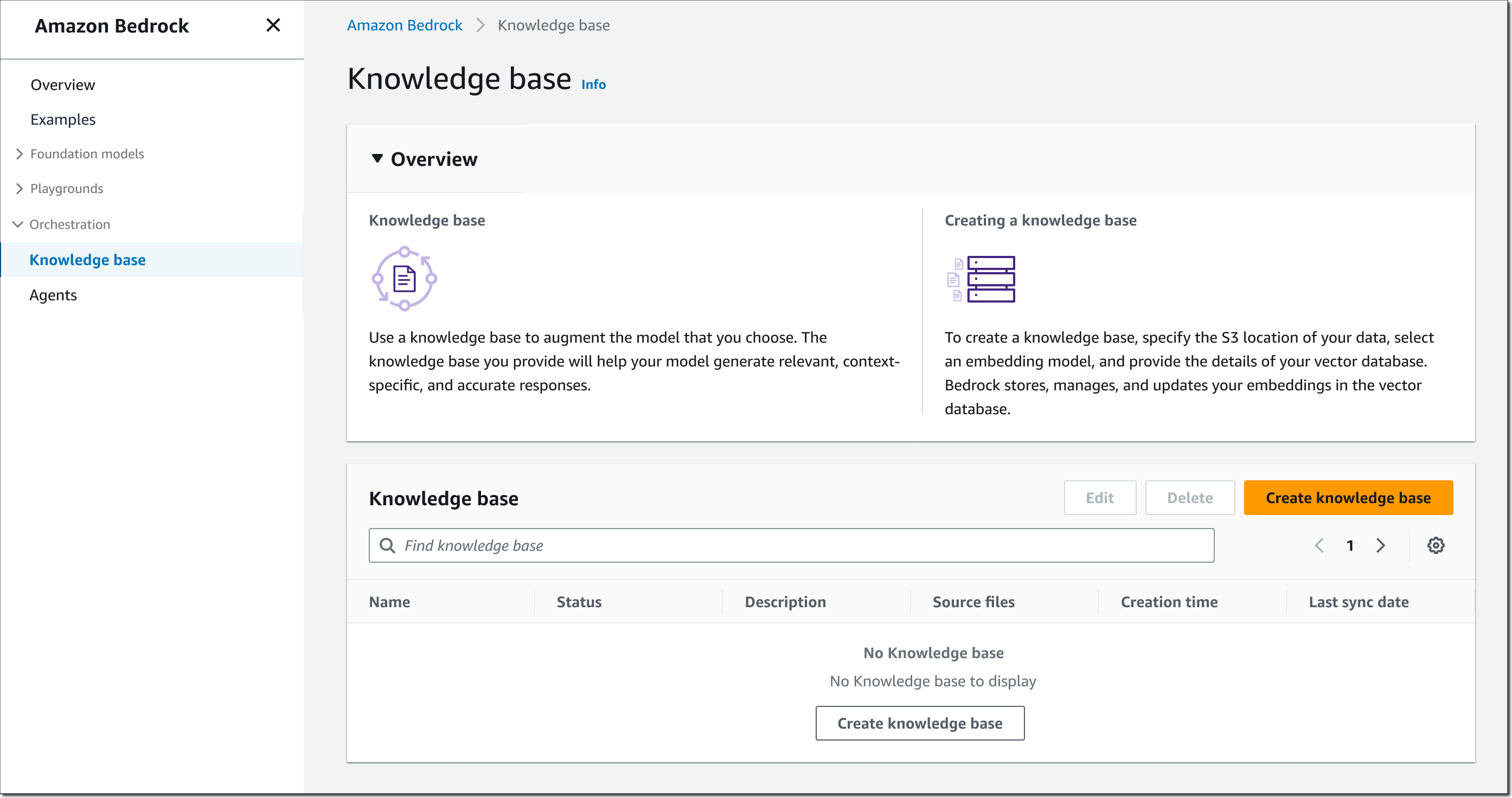
Step 1 � Present data base particulars. Enter a reputation for the data base and an outline (elective). You additionally should choose an AWS Identification and Entry Administration (IAM)�runtime function with a belief coverage for Amazon Bedrock, permissions to entry the S3 bucket you need the data base to make use of, and skim/write permissions to your vector database. You can even assign tags as wanted.

Step 2 � Arrange knowledge supply. Enter a knowledge supply title and specify the Amazon S3 location to your knowledge. Supported knowledge codecs embrace .txt, .md, .html, .doc and .docx, .csv, .xls and .xlsx, and .pdf information. You can even present an AWS Key Administration Service (AWS KMS) key to permit Bedrock to decrypt and encrypt your knowledge and one other AWS KMS key for transient knowledge storage whereas Bedrock is changing your knowledge into embeddings.
Select the embedding mannequin, resembling Amazon Titan Embeddings � Textual content, and your vector database. For the vector database, as talked about earlier, you’ll be able to select between vector engine for Amazon OpenSearch Serverless, Pinecone, or Redis Enterprise Cloud.

Vital notice on the vector database: Amazon Bedrock shouldn’t be making a vector database in your behalf. It’s essential to create a brand new, empty vector database from the checklist of supported choices and supply the vector database index title in addition to index area and metadata area mappings. This vector database will should be for unique use with Amazon Bedrock.
Let me present you what the setup seems like for vector engine for Amazon OpenSearch Serverless. Assuming you�ve arrange an OpenSearch Serverless assortment as described within the Developer Information and this AWS Huge Information Weblog publish, present the ARN of the OpenSearch Serverless assortment, specify the vector index title, and the vector area and metadata area mapping.
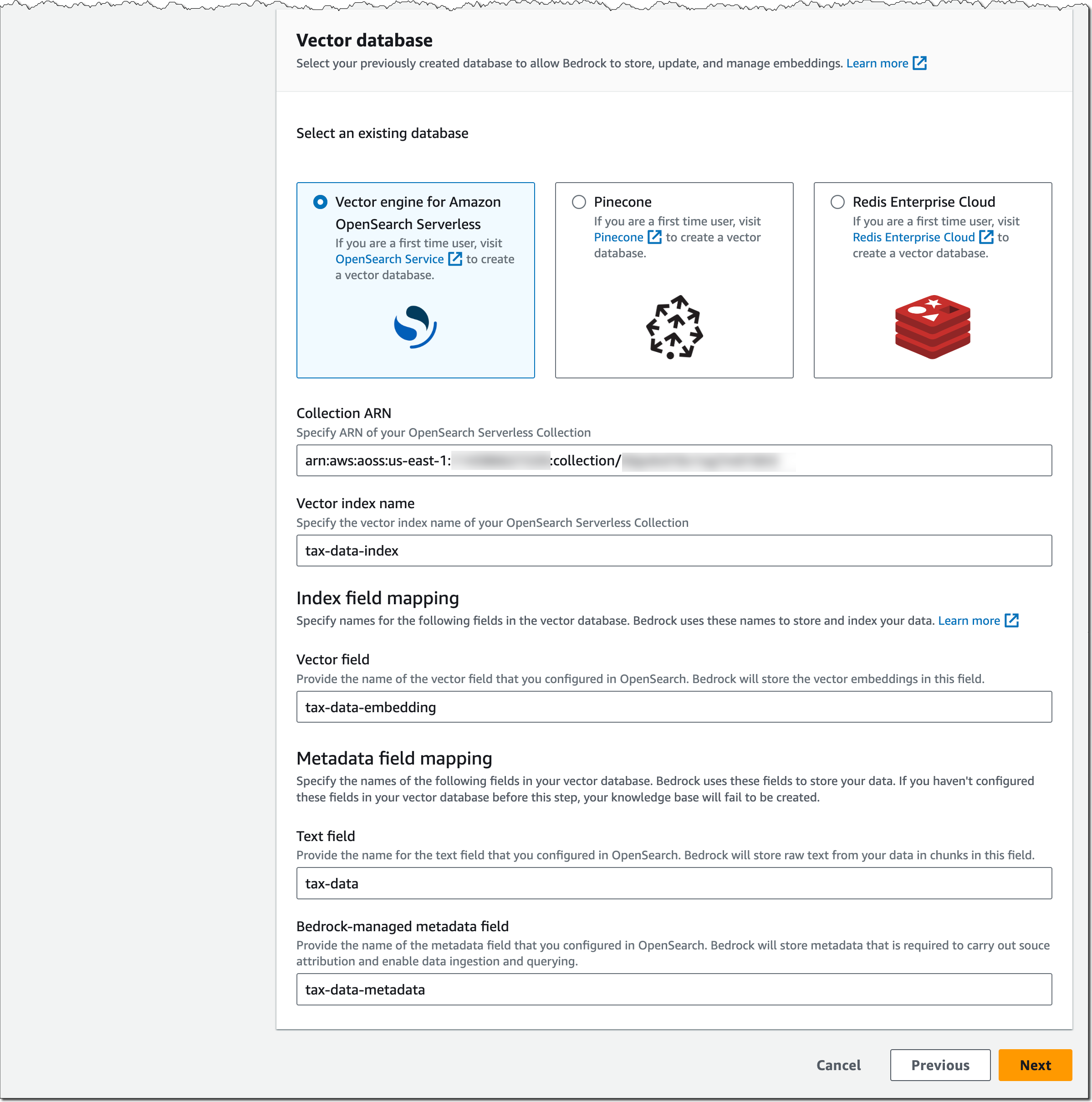
The configuration for Pinecone and Redis Enterprise Cloud is analogous. Take a look at this Pinecone weblog publish and this Redis Inc. weblog publish for extra particulars on tips on how to arrange and put together their vector database for Bedrock.
Step 3 � Assessment and create. Assessment your data base configuration and select Create data base.
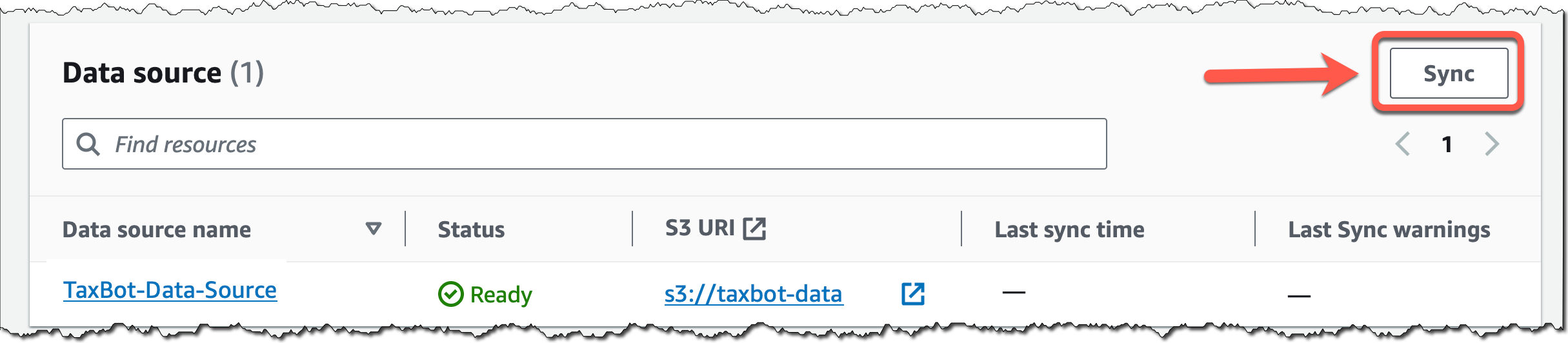
Again within the data base particulars web page, select Sync for the newly created knowledge supply, and everytime you add new knowledge to the info supply, to begin the ingestion workflow of changing your Amazon S3 knowledge into vector embeddings and upserting the embeddings into the vector database. Relying on the quantity of information, this complete workflow can take a while.
Subsequent, I�ll present you tips on how to add the data base to an agent configuration.
Add a Data Base to Brokers for Amazon Bedrock
You may add a data base when creating or updating an agent for Amazon Bedrock. Create an agent as described on this AWS Information Weblog publish on brokers for Amazon Bedrock.
For my tax bot instance, I�ve created an agent referred to as �TaxBot,� chosen a basis mannequin, and offered these directions for the agent in step 2: �You’re a useful and pleasant agent that solutions US tax submitting questions for customers.� In step 4, now you can choose a beforehand created data base and supply directions for the agent describing when to make use of this information base.

These directions are crucial as they assist the agent determine whether or not or not a specific data base needs to be used for retrieval. The agent will determine the suitable data base primarily based on person enter and out there data base directions.
For my tax bot instance, I added the data base �TaxBot-Data-Base� along with these directions: �Use this information base to reply tax submitting questions.�
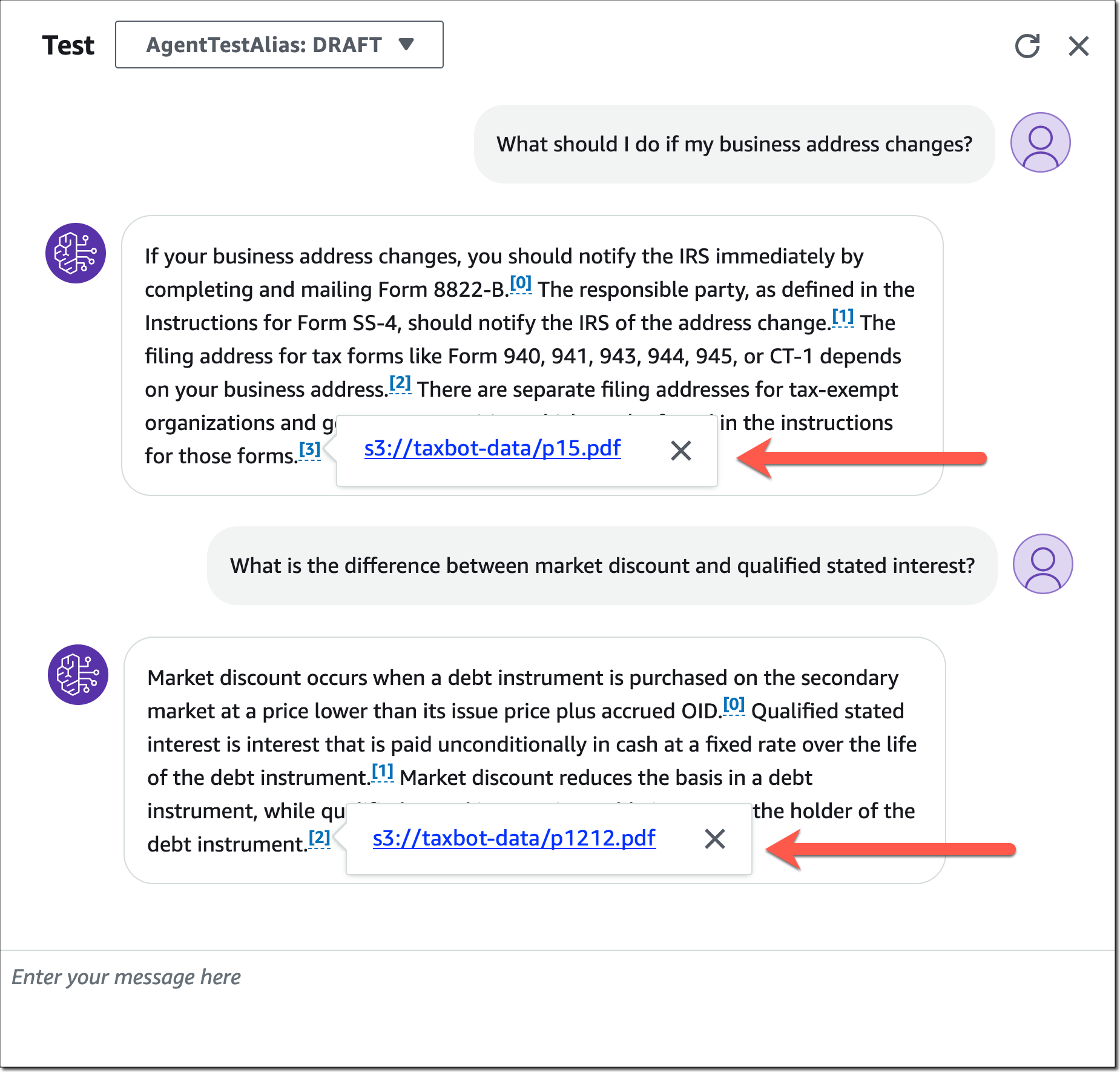
When you�ve completed the agent configuration, you’ll be able to check your agent and the way it�s utilizing the added data base. Be aware how the agent gives a supply attribution for data pulled from data bases.
 Study the Fundamentals of Generative AI
Study the Fundamentals of Generative AI
Generative AI with giant language fashions (LLMs) is an on-demand, three-week course for knowledge scientists and engineers who need to discover ways to construct generative AI functions with LLMs, together with RAG. It�s the proper basis to begin constructing with Amazon Bedrock. Enroll for generative AI with LLMs right now.
Signal as much as Study Extra about Amazon Bedrock (Preview)
Amazon Bedrock is at present out there in preview. Attain out via your regular AWS assist contacts for those who�d like entry to data bases for Amazon Bedrock as a part of the preview. We�re often offering entry to new clients. To be taught extra, go to the Amazon Bedrock Options web page and signal as much as be taught extra about Amazon Bedrock.
��Antje